This AI Paper Introduces Grounding Large Multimodal Model (GLaMM): An End-to-End Trained Large Multimodal Model that Provides Visual Grounding Capabilities with the Flexibility to Process both Image and Region Inputs
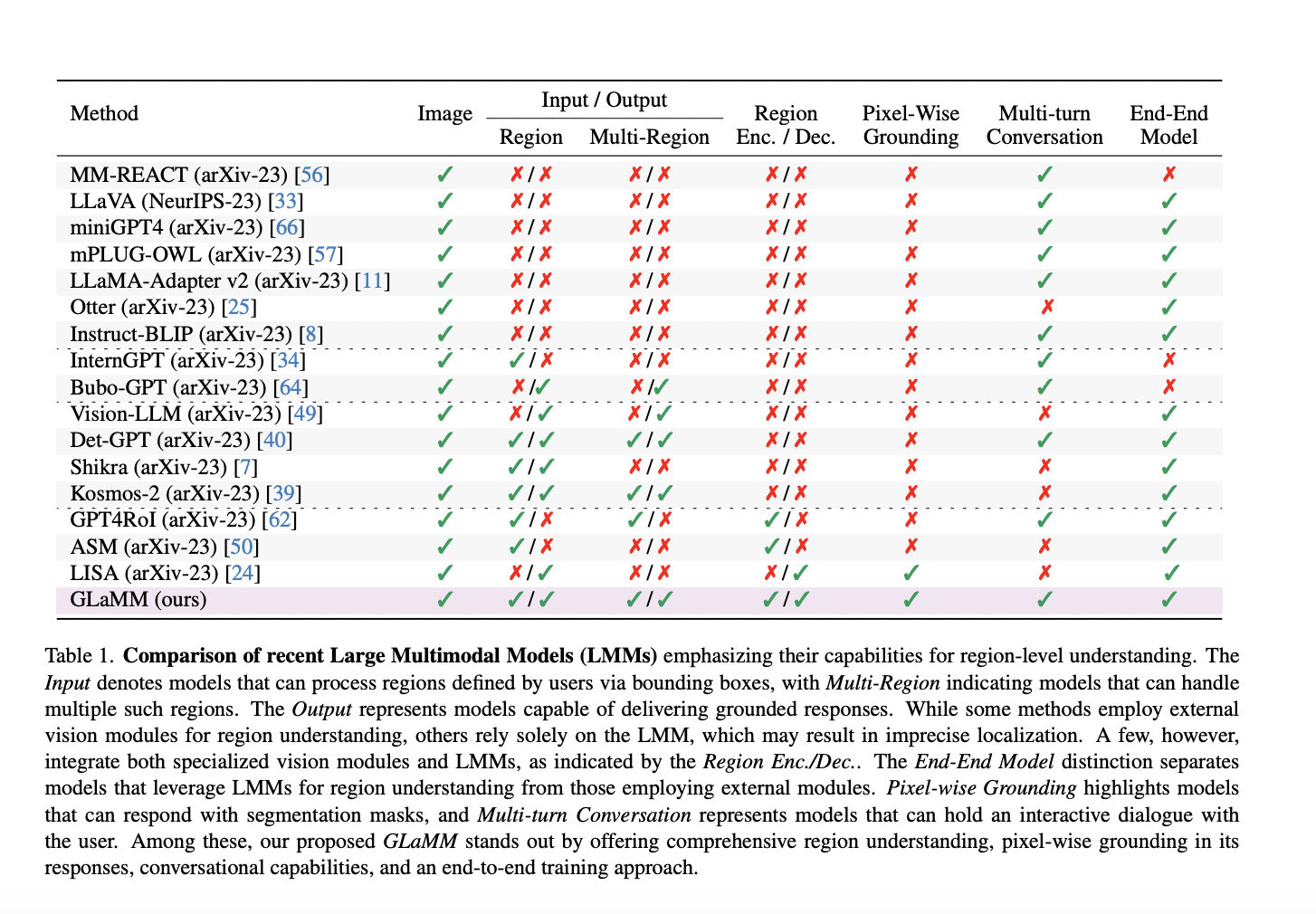
Large Multimodal Models (LMMs), propelled by the generative AI wave, have become crucial, bridging the gap between language and visual tasks. LLaVa, miniGPT4, Otter, InstructBLIP, LLaMA-Adapter v2, and mPLUGOWL are examples of early versions that show efficient textual answers depending on input photos. Despite their sophistication, these models must base their decisions on the visual environment. Advanced applications such as localized content alteration, interactive embodied agents, and deep visual understanding require this anchoring. Recent work has begun to analyze user-defined zones described using bounding boxes in models to overcome this constraint.
Although grounded text response generation has been the subject of recent efforts, they do not offer precise pixel-level groundings. In addition, attempts have been made to anchor textual descriptions in natural photographs in the relevant segmentation literature. Nevertheless, they are only able to anchor a single item. They cannot hold real, cohesive conversations, limiting their usefulness in interactive jobs requiring a thorough comprehension of written and visual material. They present Grounding LMM (GLaMM), which concurrently delivers in-depth region awareness, pixel-level groundings, and conversational abilities through an end-to-end training strategy (Fig. 1) to overcome these shortcomings of prior works.

Figure 1: GLaMM-Based Grounded Conversation Generation
Natural language replies rooted at the pixel level in the input image can be produced using the multimodal conversational model. Alongside the object attributes (white house, red roof, well-kept lawn) and object relationships (grass extending to the pavement, sky over the building), various levels of granularity are represented in the output groundings, such as things (building, tree), stuff (grass, sky, pavement), and object parts (roof as a subpart of the building).
They provide the unique job of Grounded Conversation Generation (GCG) to address the dearth of standards for visually grounded talks. The GCG job aims to generate object segmentation masks interspersed with natural language replies. This difficult problem combines various computer vision tasks usually handled separately, such as phrase grounding, picture and region-level captioning, referencing expression segmentation, and vision-language interactions. As a result, their combined model and suggested pretraining dataset may be used successfully for several downstream tasks (such as conversational-style QA, region-level captioning, picture captioning, and expression segmentation).
Researchers from Mohamed bin Zayed University of AI, Australian National University, Aalto University Carnegie Mellon University, University of California – Merced, Linköping University and Google Research introduce GLaMM, the first model created especially for this difficult task. In contrast to previous efforts, GLaMM provides a varied user experience by working with textual and visual suggestions and providing visually grounded outcomes. The tedious task of gathering extensive annotations for picture areas is necessary for detailed comprehension at the region level. They suggest an automated workflow to annotate the extensive Grounding-anything Dataset (GranD) to reduce the labor-intensive manual labeling process. GranD uses a computerized pipeline with certain verification processes and has 7.5 million distinct ideas anchored in 810 million areas, each with a segmentation mask.
The dataset annotates SAM photos using a multi-level hierarchical method, utilizing cutting-edge vision and language models to improve annotation quality. GranD redefines comprehensiveness with its 11 million photos and qualities, such as 33 million grounded captions and 84 million reference terms. They offer the first high-quality dataset for grounded conversations and the automatically generated GCG dataset. This dataset was created by repurposing the previously available manually annotated datasets for the GCG using GPT-4 in-context learning. They designate the large-scale automatically generated data as GranDp and the high-quality dataset as GranDf, indicating that it is suitable for finetuning. GLaMM is trained in pretraining-finetuning phases using GranDf and GranDp.
In conclusion, their research has three primary contributions:
• Grounding Large Multimodal Model (GLaMM) Introduction: This is a first-of-its-kind model that can provide natural language replies that are smoothly combined with object segmentation masks. In contrast to current models, GLaMM supports optional visual cues and textual ones, enabling improved multimodal user engagement.
• New Task and Assessment Criteria: Acknowledging the absence of established standards for visually grounded dialogues, they put forth a novel job called Grounded Conversation Generation (GCG). In addition, they close a large gap in the literature by introducing an extensive assessment process to assess the performance of models in this unique scenario that integrates several separate tasks.
• Grounding-anything Dataset (GranD): They develop GranD, a massively densely annotated dataset, to aid in model training and assessment. It was created using an automatic annotation pipeline and verification standards, and it has 7.5 million distinct ideas based on 810 million locations. Furthermore, they repurpose existing open-source datasets to create GranDf, a high-quality dataset specifically created for the GCG task fine-tuning.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.