This AI Paper Introduces Learning from Mistakes (LeMa): Enhancing Mathematical Reasoning in Large Language Models through Error-Driven Learning
Human beings, as inherently fallible creatures, navigate the intricate journey of life marked by successes and failures. In the grand tapestry of our existence, the thread of mistakes weaves a unique pattern that contributes significantly to our growth and development. Learning from mistakes is fundamental to the human experience, shaping our character, fostering resilience, and propelling us toward a more enlightened future.
Can LLM also learn from mistakes? Is it possible? Yes, they do. Large language models, like GPT-3, learn from vast data, including examples of correct and incorrect language usage. These models are trained on diverse datasets containing a wide range of text from the internet, books, articles, and more. The model learns to recognize the training data’s patterns, relationships, and contextual information. It understands grammar, syntax, semantics, and even nuances of language use.
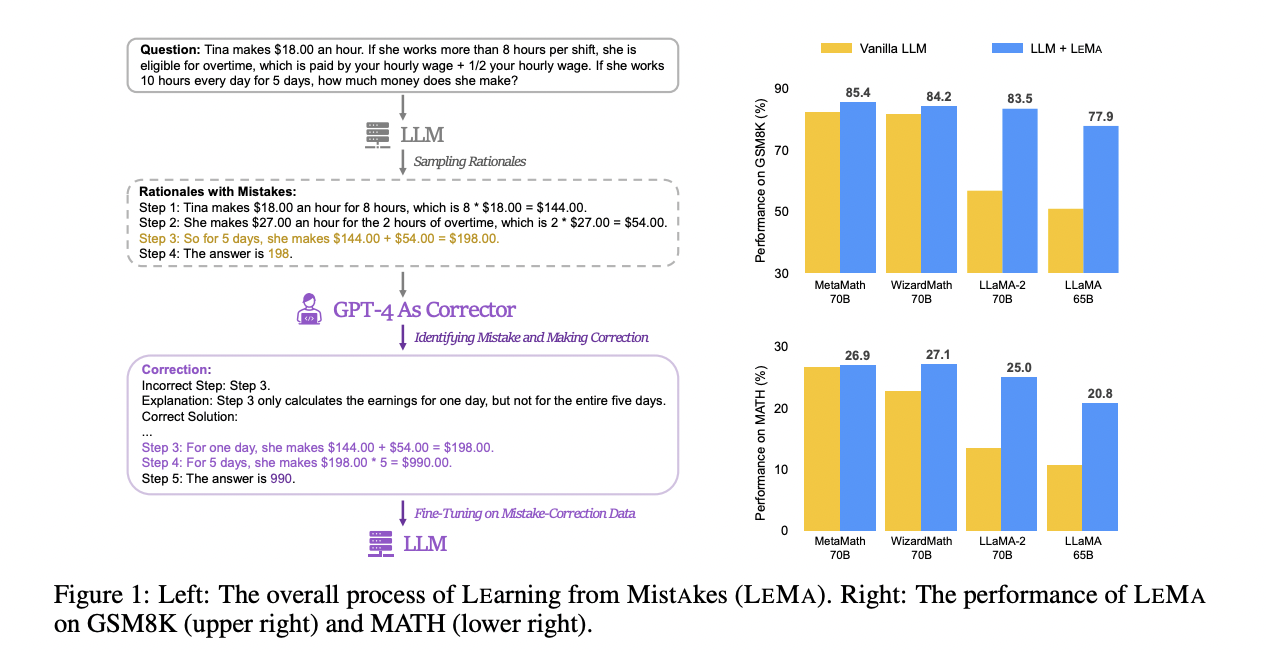
Mimicking this error-driven learning process, researchers at Jiaotong University, Peking University, and Microsoft present LEMA, which fine-tunes LLMs on mistake correction data pairs generated by GPT-4. They say their idea of motivation came from the learning process of human students from mistakes.
Their method involves generating mistake-correction data pairs and then fine-tuning LLMs using correction data. They employ multiple LLMs, such as LLaMA and GPT series models, to collect inaccurate reasoning paths to generate correction data. The generated corrections contain three pieces of information about the incorrect step in the original solution, an explanation of why this step is incorrect, and how to correct the original solution to arrive at the correct final answer.
They filter out the corrections with incorrect final answers, and they say this process exhibits adequate quality for the subsequent fine-tuning stage. They generate more reasoning paths for each question in the training set with GPT-4 and filter out paths with wrong final answers. They apply this CoT data augmentation to set up a strong fine-tuning baseline that only utilizes CoT data. It also facilitates further ablation study on controlling data size for fine-tuning. They fine-tune the model on question-rational data alone.
Compared to fine-tuning on CoT data alone, LEMA consistently improves performance across various LLMs and tasks. LEMA with LLaMA-2-70B achieves 83.5% on GSM8K and 25.0% on MATH, while fine-tuning on CoT data alone yields 81.4% and 23.6%, respectively.
Recent advancements in LLMs have enabled them to perform a step-by-step approach to problem-solving. However, this multi-step generation process does not inherently imply that LLMs possess strong reasoning capabilities, as they may merely emulate the superficial behavior of human reasoning without genuinely comprehending the underlying logic and rules necessary for precise rationale. LEMA employs GPT-4 as a world model to teach smaller models to adhere to logic and rules rather than merely mimic the step-by-step behavior.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.