This AI Paper Introduces MVControl: A Neural Network Architecture Revolutionizing Controllable Multi-View Image Generation and 3D Content Creation
Recently, there have been remarkable advancements in 2D picture production. Input text prompts make it simple to produce high-fidelity graphics. Success in text-to-image creation is seldom transferred to the text-to-3D domain because of the need for 3D training data. Due to the nice properties of diffusion models and differentiable 3D representations, recent score distillation optimization (SDS) based methods aim to distill 3D knowledge from a pre-trained large text-to-image generative model and have achieved impressive results instead of training a large text-to-3D generative model from scratch with large amounts of 3D data. DreamFusion is an exemplary work that introduces a novel approach to 3D asset creation.
Over the last year, the methodologies have swiftly evolved, according to the 2D-to-3D distillation paradigm. Numerous studies have been put forth to improve the generation quality by applying multiple optimization stages, concurrently optimizing the diffusion before the 3D representation, formulating the score distillation algorithm with greater precision, or improving the specifics of the entire pipeline. While the approaches above can yield fine textures, ensuring view consistency in produced 3D content is difficult since the 2D diffusion prior is not dependent. As a result, several efforts have been made to force multi-view information into the pre-trained diffusion models.
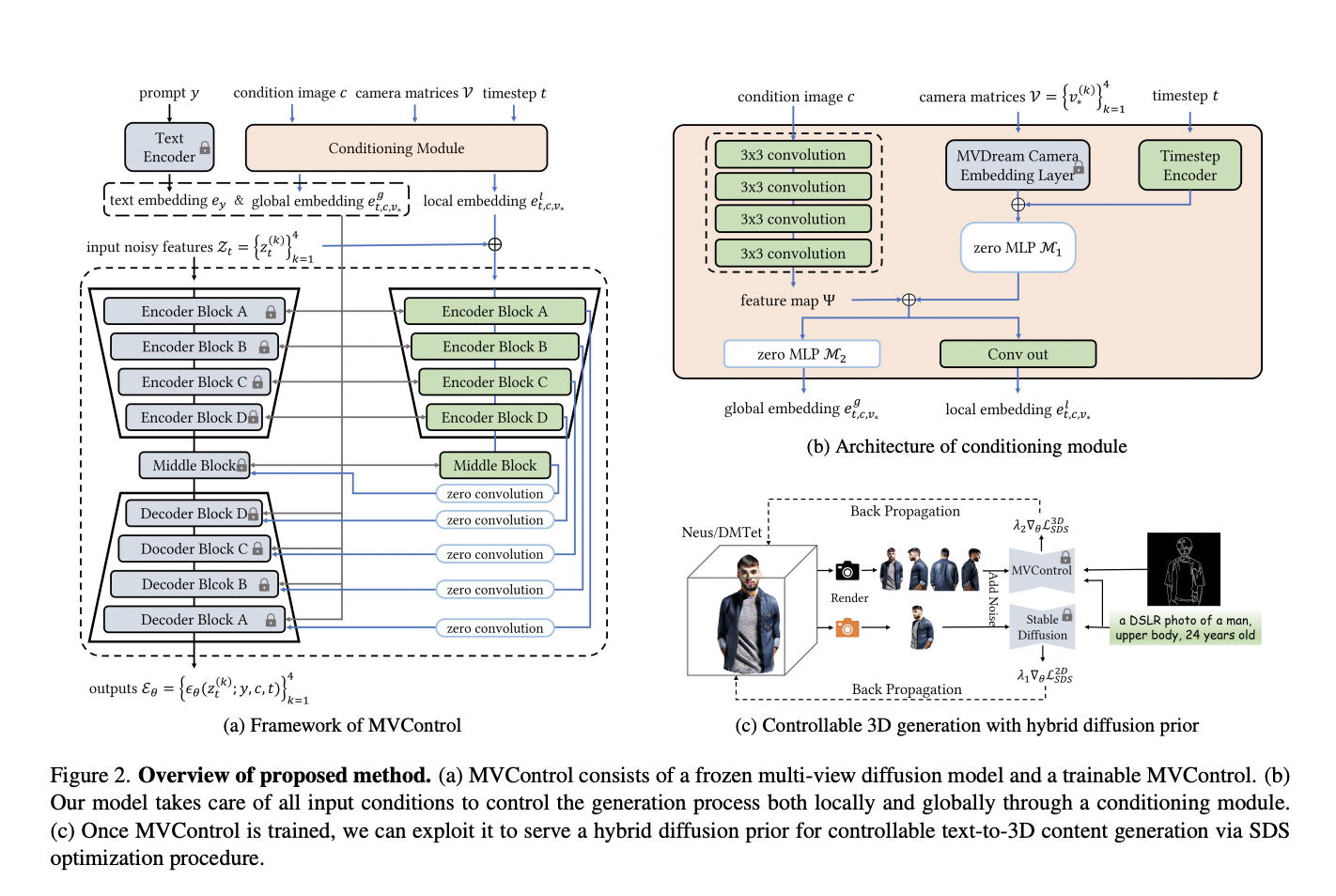
The base model is then integrated with a control network to enable controlled text-to-multi-view picture production. Similarly, the research team merely trained the control network, and the weights of MVDream were all frozen. The research team discovered experimentally that the relative pose condition concerning the condition picture is better for controlling text-to-multi-view generation, even if MVDream is trained with camera poses described in the absolute world coordinate system. That is at odds with the pretrained MVDream network’s description, though. Furthermore, view consistency can only be readily achieved by directly adopting 2D ControlNet’s control network to interact with the base model since its conditioning mechanism is built for single image creation and needs to consider the multi-view situation.
The base model is then integrated with a control network to enable controlled text-to-multi-view picture production. Similarly, the research team merely trained the control network, and the weights of MVDream were all frozen. The research team discovered experimentally that the relative pose condition concerning the condition picture is better for controlling text-to-multi-view generation, even if MVDream is trained with camera poses described in the absolute world coordinate system. That is at odds with the pretrained MVDream network’s description, though. Furthermore, view consistency can only be readily achieved by directly adopting 2D ControlNet’s control network to interact with the base model since its conditioning mechanism is built for single image creation and needs to consider the multi-view situation.
To address these problems, the research team from Zhejiang University, Westlake University, and Tongji University created a unique conditioning technique based on the original ControlNet architecture, which is straightforward but successful enough to provide controlled text-to-multi-view generation. A portion of the extensive 2D dataset LAION and 3D dataset Objaverse are jointly used to train MVControl. In this study, the research team investigated using the edge map as a conditional input. Their network, however, is unlimited in its ability to employ different kinds of input circumstances, such as depth maps, sketch images, etc. Once trained, the research team can use MVControl to give 3D priors for controlled text-to-3D asset production. Specifically, the research team use a hybrid diffusion prior based on an MVControl network and a pretrained Stable-Diffusion model. There is a coarse-to-fine generation process. The research team only optimizes the texture at the fine step when the research team have a decent geometry from the coarse stage. Their comprehensive tests show that their suggested approach can use an input condition image and a written description to produce high-fidelity, fine-grain controlled multi-view images and 3D content.
To sum up, the following are their primary contributions.
• After their network is trained, it may be used as a component of a hybrid diffusion before controlling text-to-3D content synthesis via SDS optimization.
• The research team suggests a unique network design to enable fine-grain controlled text-to-multi-view picture generation.
• Their approach can produce high-fidelity multi-view images and 3D assets that can be fine-grain controlled by an input condition image and text prompt, as shown by extensive experimental results.
• In addition to generating 3D assets through SDS optimization, their MVControl network could be useful for various applications in the 3D vision and graphic community.
Check out the Paper, Project, and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.