This AI Paper Introduces Neural MMO 2.0: Revolutionizing Reinforcement Learning with Flexible Task Systems and Procedural Generation
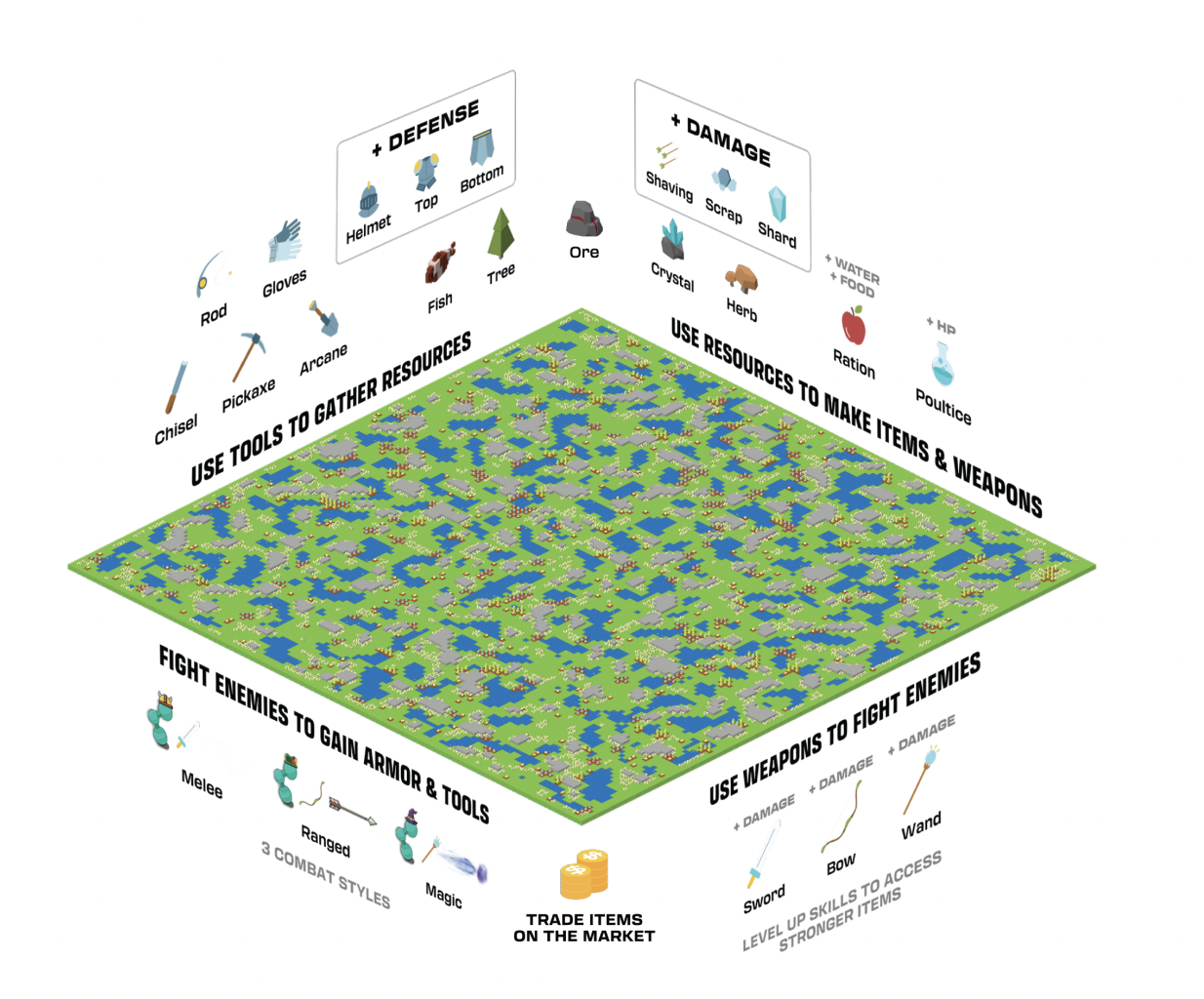
Researchers from MIT, CarperAI, and Parametrix.AI introduced Neural MMO 2.0, a massively multi-agent environment for reinforcement learning research, emphasizing a versatile task system enabling users to define diverse objectives and reward signals. The key enhancement involves challenging researchers to train agents capable of generalizing to unseen tasks, maps, and opponents. Version 2.0 is a complete rewrite, ensuring compatibility with CleanRL and offering enhanced capabilities for training adaptable agents.
Between 2017 and 2021, the development of Neural MMO brought forth influential environments like Griddly, NetHack, and MineRL, which were compared in great detail in a previous publication. After 2021, newer environments such as Melting Pot and XLand came into existence and expanded the scope of multi-agent learning and intelligence evaluation scenarios. Neural MMO 2.0 boasts of improved performance and features a versatile task system that allows for the definition of diverse objectives.
Neural MMO 2.0 is an advanced multi-agent environment that allows users to define a wide range of objectives and reward signals via a flexible task system. The platform has undergone a complete rewrite and now provides a dynamic space for studying complex multi-agent interactions and reinforcement learning dynamics. The task system comprises three core modules – GameState, Predicates, and Tasks – providing structured game state access. Neural MMO 2.0 is a powerful tool for exploring multi-agent interactions and reinforcement learning dynamics.
Neural MMO 2.0 implements the PettingZoo ParallelEnv API and leverages CleanRL’s Proximal Policy Optimization. The platform features three interconnected task system modules: GameState, Predicates, and Tasks. The GameState module accelerates simulation speeds by hosting the entire game state in a flattened tensor format. With 25 built-in predicates, researchers can articulate intricate, high-level objectives, and auxiliary data stores capture event data to expand the task system’s capabilities efficiently. With a three-fold performance improvement over its predecessor, the platform is a dynamic space for studying complex multi-agent interactions, resource management, and competitive dynamics in reinforcement learning.
Neural MMO 2.0 represents a significant advancement, featuring enhanced performance and compatibility with popular reinforcement learning frameworks, including CleanRL. The platform’s flexible task system makes it a valuable tool for studying intricate multi-agent interactions, resource management, and competitive dynamics in reinforcement learning. Neural MMO 2.0 encourages new research, scientific exploration, and progress in multi-agent reinforcement learning. Designed for computational efficiency, it enables faster simulation speeds and efficient data selection for objective definition.
Future research in Neural MMO 2.0 can focus on exploring generalization across unseen tasks, maps, and adversaries, challenging researchers to train adaptable agents for new environments. The platform’s potential extends to supporting more intricate environments, enabling studying diverse learning and intelligence aspects. Continuous enhancements and adaptations are recommended to ensure ongoing support and development, fostering an active user community. Integration with additional reinforcement learning frameworks can enhance accessibility, and further advancements in computational efficiency can improve simulation speeds and data generation for reinforcement learning studies.
Check out the Paper, Project, and Demo. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.