This AI Paper Introduces Relax: A Compiler Abstraction for Optimizing End-to-End Dynamic Machine Learning Workloads
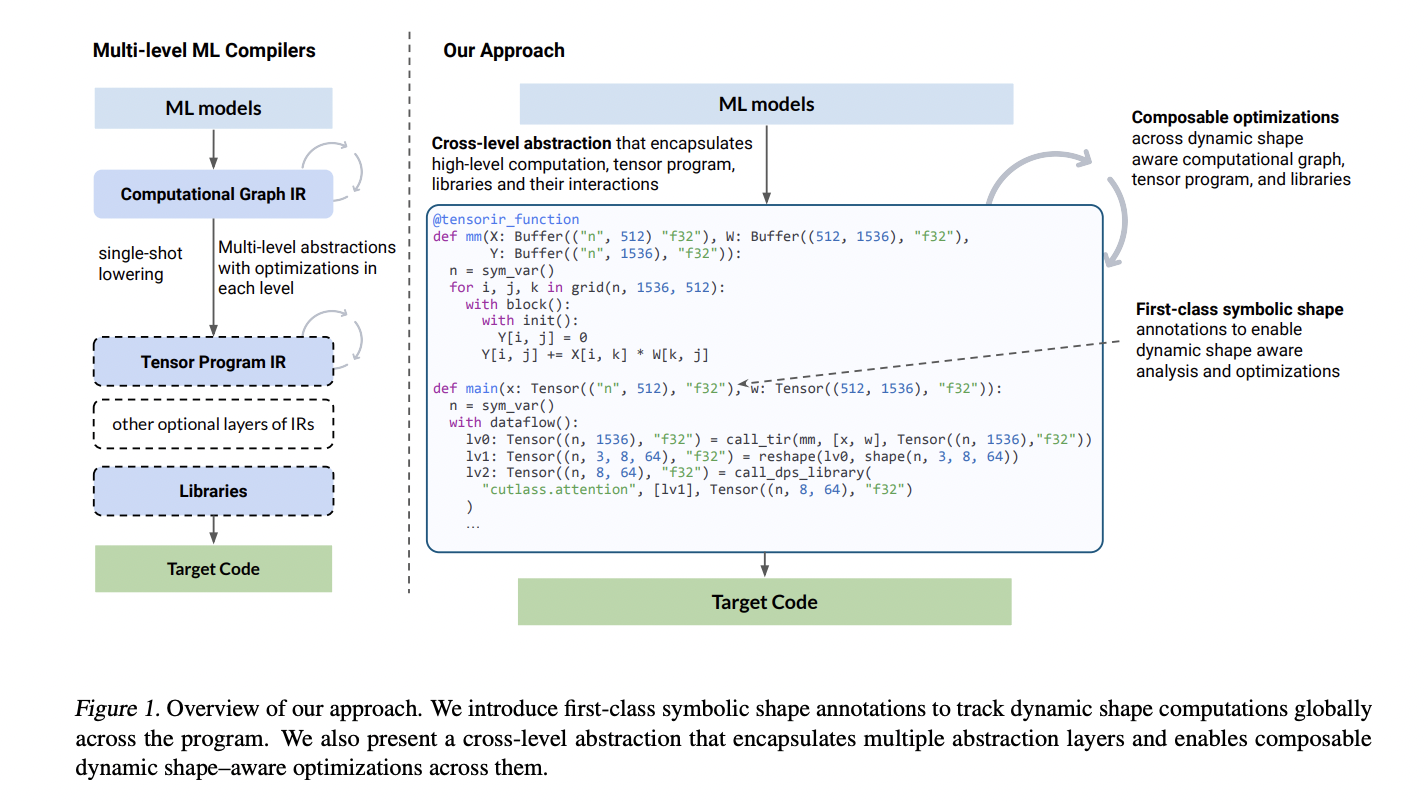
Optimizing machine learning models with dynamic shapes can be crucial for achieving better performance and flexibility. Dynamic shapes refer to the ability of a model to handle input data with varying dimensions during runtime. Users utilize frameworks that support dynamic computation graphs, such as TensorFlow’s eager execution or PyTorch. These frameworks allow building models that can adapt to variable input sizes during runtime.
There are many challenges in optimizing machine learning models with dynamic shapes, as many traditional optimizations depend on static shape analysis. The missing information from dynamic dimensions can significantly affect the optimizations one can perform across operators and functions. Models with dynamic shapes need to handle varying batch sizes. Optimizing for different batch sizes can be more challenging than optimizing for a fixed batch size, particularly in production settings.
Current machine learning (ML) compilers usually lower programs to hardware in a traditional single-shot lowering flow, applying one optimization after the other, typically rewriting the program into a lower-level representation. This approach often results in losing shape and additional information between abstraction layers, making it harder to perform incremental optimizations across boundaries.
Researchers present Relax. It is a compiler abstraction for optimizing end-to-end dynamic machine learning workloads. It has first-class symbolic shape annotations to track dynamic shape computations globally across the program. It also has a cross-level abstraction that encapsulates computational graphs, loop-level tensor programs, and library calls in a single representation to enable cross-level optimizations. It is an end-to-end compilation framework to optimize dynamic shape models.
Researchers adopt a forward deduction method that deduces the annotation of an expression based on its input components. Forward deduction is simple and local, and one can obtain annotations for temporary variables during compiler passes. Additionally, when shapes cannot be inferred automatically, the forward deduction can use the results of a user-inserted match cast to continue inferring later annotations.
Researchers say all optimizations in Relax are performed as composable dynamic shape–aware transformations. This incrementally optimizes or partially lowers portions of the computation using different approaches. It considers analysis from other levels and incorporates further optimizations that assume dynamic shape relations.
Experimental results show that Relax compiles and optimizes emerging LLMs onto diverse hardware backends, delivering competitive performance to heavily optimized platform-specific solutions. Additionally, Relax supports LLMs on a broad set of devices and environments, including mobile phones, embedded devices, and web browsers through WebAssembly and WebGPU.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.