This AI Paper Introduces RMT: A Fusion of RetNet and Transformer, Pioneering a New Era in Computer Vision Efficiency and Accuracy
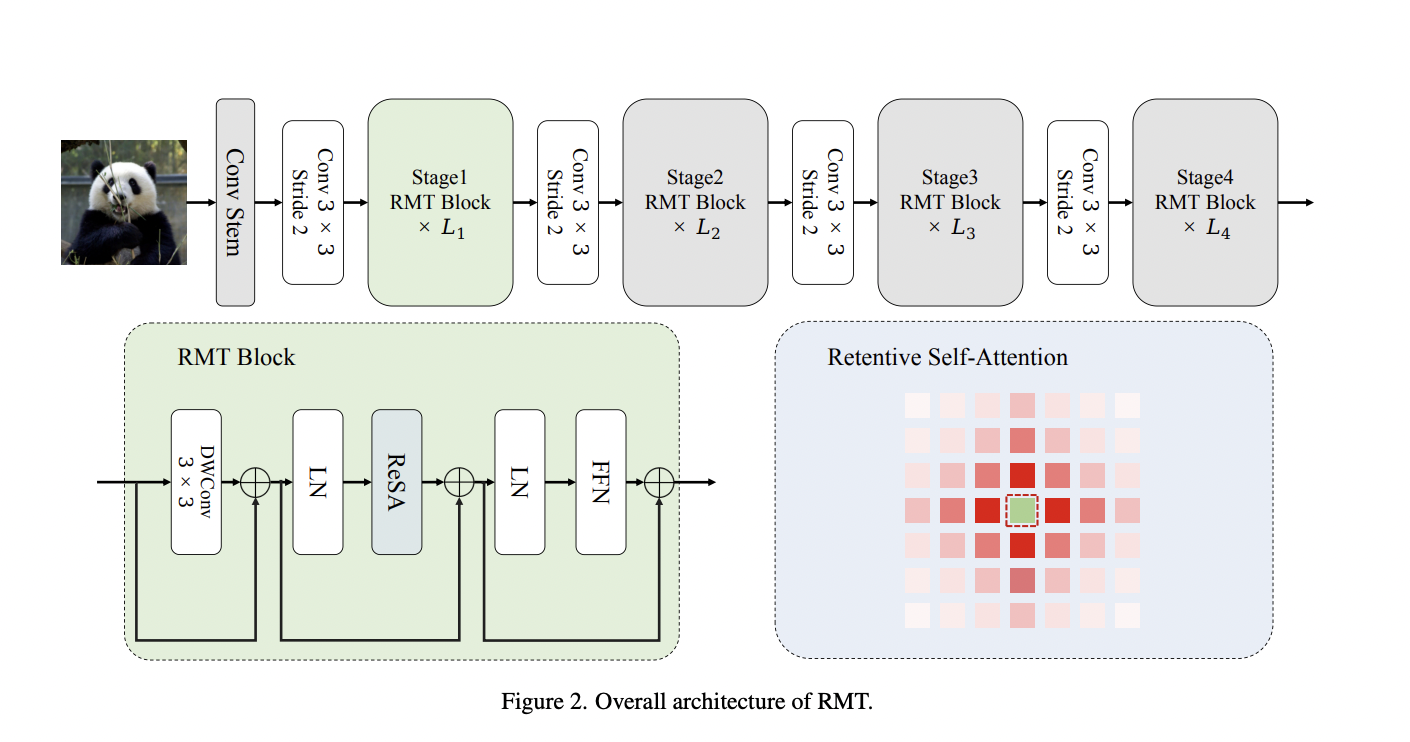
After debuting in NLP, Transformer was transferred to the sphere of computer vision, where it proved particularly effective. In contrast, the NLP community has recently become very interested in Retentive Network (RetNet), a design that can potentially replace Transformer. Chinese researchers have questioned whether or not applying the RetNet concept to vision will result in a similarly impressive performance. To solve this problem, they propose RMT, a hybrid of RetNet and Transformer. RMT, influenced by RetNet, adds explicit decay to the vision backbone, allowing the vision model to use previously acquired knowledge about spatial distances. This distance-related spatial prior permits precise regulation of each token’s perceptual bandwidth. They also decompose the modeling process along the image’s two coordinate axes, which helps to lower the computing cost of global modeling.
Extensive experiments have shown that the RMT excels at various computer vision tasks. For instance, with only 4.5G FLOPS, RMT obtains 84.1% Top1-acc on ImageNet-1k. When models are roughly the same size and are trained using the same technique, RMT consistently produces the greatest Top1-acc. In downstream tasks like object detection, instance segmentation, and semantic segmentation, RMT greatly outperforms existing vision backbones.
Extensive experiments show that the proposed strategy works; therefore, the researchers back up their claims. The RMT achieves dramatically better results on image classification tasks than state-of-the-art (SOTA) models. The model outperforms competing models on various tasks, including object detection and instance segmentation.
The following have made contributions:
- Researchers incorporate spatial prior knowledge about distances into vision models, bringing the key process of the Retentive Network, retention, to the two-dimensional setting. Retentive SelfAttention (ReSA) is the name of the new mechanism.
- To simplify its computation, researchers decompose ReSA along two image axes. This decomposition strategy efficiently reduces the required computational effort with negligible effects on the model’s efficiency.
- Extensive testing has proven RMT’s superior performance. RMT shows particularly strong benefits in downstream tasks like object detection and instance segmentation.
In a nutshell, researchers suggest RMT, a vision backbone that combines a retentive network and a Vision Transformer. With RMT, spatial prior knowledge is introduced to visual models in the form of explicit decay related to distance. The acronym ReSA describes the novel process of improved memory retention. RMT also uses a technique that decomposes the ReSA into two axes to simplify the model. Extensive experiments confirm RMT’s efficiency, particularly in downstream tasks like object detection, where RMT shows notable advantages.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.