This AI Paper Introduces Sub-Sentence Encoder: A Contrastively-Learned Contextual Embedding AI Model for Fine-Grained Semantic Representation of Text
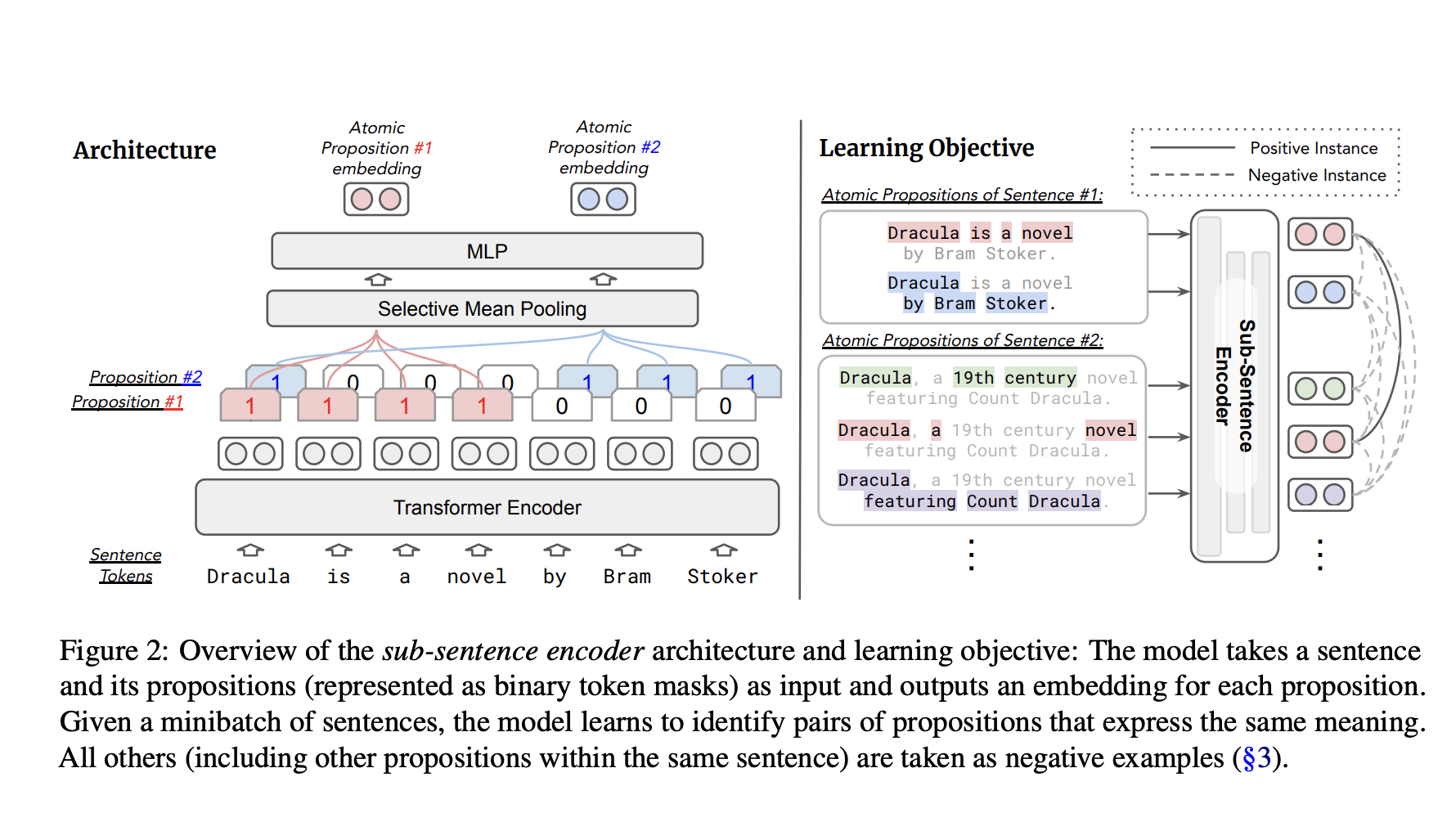
Researchers from the University of Pennsylvania, the University of Washington, and Tencent AI Lab propose a sub-sentence encoder, a contrastively learned contextual embedding model that generates distinct embeddings for atomic propositions within a text sequence. Unlike traditional sentence embeddings, it focuses on fine-grained semantic representation by learning contextual embeddings for different units of meaning. The model is effective in tasks like retrieving supporting facts and recognizing conditional semantic similarity. Sub-sentence encoders maintain similar inference cost and space complexity as sentence encoders, showcasing practical viability.
The sub-sentence encoder focuses on fine-grained semantic representation by generating distinct embeddings for atomic propositions within text sequences. Applications include retrieving supporting facts and recognizing conditional semantic similarity. Efficient encoding on a granular level is expected to impact text evaluation, attribution, and factuality estimation. The sub-sentence encoder design, influenced by text attribution needs, has potential applications in cross-document information linking.
The study challenges the common practice of encoding entire text sequences into fixed-length vectors by introducing a sub-sentence encoder. With potential applications in cross-document information linking, the sub-sentence encoder architecture offers versatility for tasks with varying information granularity. The research aims to assess the utility of sub-sentence encoders in tasks like retrieving supporting facts and recognizing conditional semantic textual similarity.
The model generates distinct contextual embeddings for different atomic propositions within a text sequence. Using binary token masks as inputs, a transformer-based architecture applies the sub-sentence encoder to retrieve supporting facts for text attribution and recognize conditional semantic textual similarity. While acknowledging experimental limitations in English text, the study outlines the potential for broader language applicability and introduces an automatic process for creating training data for sub-sentence encoders.
The sub-sentence encoder surpasses sentence encoders in recognizing nuanced semantic differences between propositions in the same context, with improvements in precision and recall. The sub-sentence encoder performs comparably to document-level and sentence-level models in atomic fact retrieval, showing enhanced memory. The study emphasizes the sub-sentence encoder’s potential for multi-vector retrieval across different granularities, suggesting versatility in various retrieval tasks.
The architecture holds promise for cross-document information linking and various tasks with diverse granularity. Evaluation of atomic fact retrieval showcases its utility in retrieving supporting propositions. The sub-sentence encoder improves recall for multi-vector recovery, underscoring its potential for various retrieval tasks. The study highlights its significance in addressing granularity challenges in-text attribution.
The research suggests that the demonstrated findings could pave the way for further research in long-form text evaluation, attribution, and factuality estimation. Acknowledging the limited scale of experiments in English text, the study proposes future work on exploring a multilingual sub-sentence encoder, indicating potential extensions to other languages. Emphasizing the need for ongoing exploration, the study hopes the work will inspire advancements in sub-sentence encoder applications, encouraging further research in this domain.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.