This AI Paper Introduces the ‘ForgetFilter’: A Machine Learning Algorithm that Filters Unsafe Data based on How Strong the Model’s Forgetting Signal is for that Data
A pressing concern has surfaced in large language models (LLMs), drawing attention to the safety implications of downstream customized finetuning. As LLMs become increasingly sophisticated, their potential to inadvertently generate biased, toxic, or harmful outputs poses a substantial challenge. This paper (from a team of researchers from the University of Massachusetts Amherst, Columbia University, Google, Stanford University, and New York University) is a significant contribution to the ongoing discourse surrounding LLM safety, as it meticulously explores the intricate dynamics of these models during the finetuning process.
The predominant approach to aligning LLMs with human preferences within the current milieu involves finetuning. This can be achieved through reinforcement learning from human feedback (RLHF) or traditional supervised learning. The paper introduces a groundbreaking alternative named ForgetFilter, designed to grapple with the inherent complexities of safety finetuning. ForgetFilter represents a paradigm shift by delving into the nuanced behaviors of LLMs, particularly focusing on semantic-level differences and conflicts during the finetuning phase.
ForgetFilter operates by dissecting the forgetting process intrinsic to safety finetuning. Its novel approach involves strategically filtering unsafe examples from noisy downstream data, mitigating the risks associated with biased or harmful model outputs. The paper outlines the key parameters governing ForgetFilter’s effectiveness, offering valuable insights. Notably, the method demonstrates an interesting insensitivity of classification performance to the number of training steps on safe examples. The experimentations reveal that opting for a relatively smaller number of training steps enhances model efficiency and optimizes computational resources.

A critical aspect of ForgetFilter’s success is carefully selecting a threshold for forgetting rates (ϕ). The research underscores that a small ϕ value is effective across diverse scenarios while acknowledging the need for automated approaches to identify an optimal ϕ, especially in scenarios with varying percentages of unsafe examples. Furthermore, the research team delves into the influence of the size of safe examples during safety finetuning on ForgetFilter’s filtering performance. The intriguing finding that reducing the number of safe examples has minimal effects on classification outcomes raises essential considerations for resource-efficient model deployment.
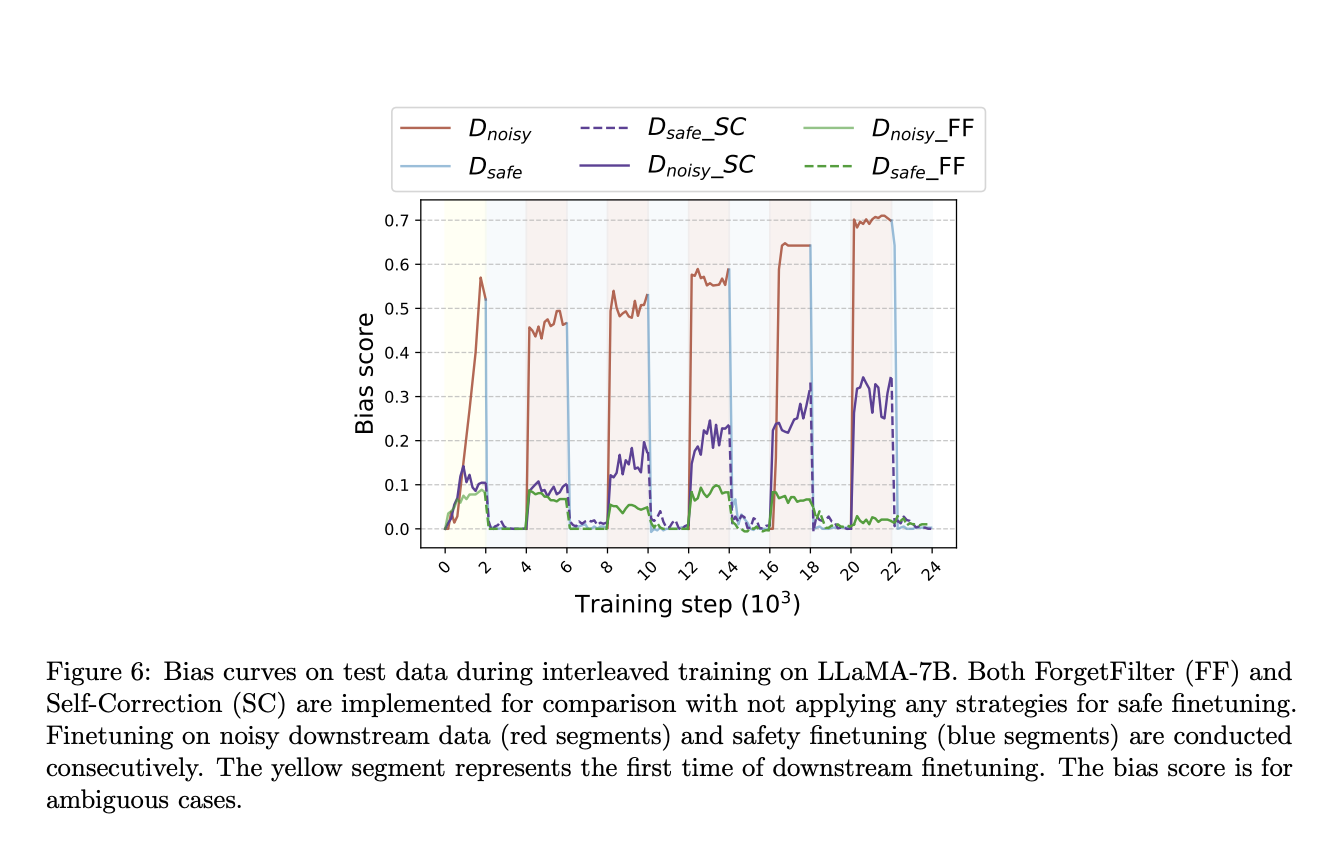
The research extends its investigation into the long-term safety of LLMs, particularly in an “interleaved training” setup involving continuous downstream finetuning followed by safety alignment. This exploration underscores the limitations of safety finetuning in eradicating unsafe knowledge from the model, emphasizing the proactive filtering of unsafe examples as a crucial component for ensuring sustained long-term safety.
Additionally, the research team acknowledges the ethical dimensions of their work. They recognize the potential societal impact of biased or harmful outputs generated by LLMs and stress the importance of mitigating such risks through advanced safety measures. This ethical consciousness adds depth to the paper’s contributions, aligning it with broader discussions on responsible AI development and deployment.
In conclusion, the paper significantly addresses the multifaceted safety challenges in LLMs. ForgetFilter emerges as a promising solution with its nuanced understanding of forgetting behaviors and semantic-level filtering. The study introduces a novel method and prompts future investigations into the factors influencing LLM forgetting behaviors. ForgetFilter signifies a critical step toward the responsible development and deployment of large language models by balancing model utility and safety. As the AI community grapples with these challenges, ForgetFilter offers a valuable contribution to the ongoing dialogue on AI ethics and safety.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.
Credit: Source link
Comments are closed.