This AI Paper Introduces the Open-Vocabulary SAM: A SAM-Inspired Model Designed for Simultaneous Interactive Segmentation and Recognition
Combining CLIP and the Segment Anything Model (SAM) is a groundbreaking Vision Foundation Models (VFMs) approach. SAM performs superior segmentation tasks across diverse domains, while CLIP is renowned for its exceptional zero-shot recognition capabilities.
While SAM and CLIP offer significant advantages, they also come with inherent limitations in their original designs. SAM, for instance, cannot recognize the segments it identifies. On the other hand, CLIP, trained using image-level contrastive losses, faces challenges in adapting its representations for dense prediction tasks.
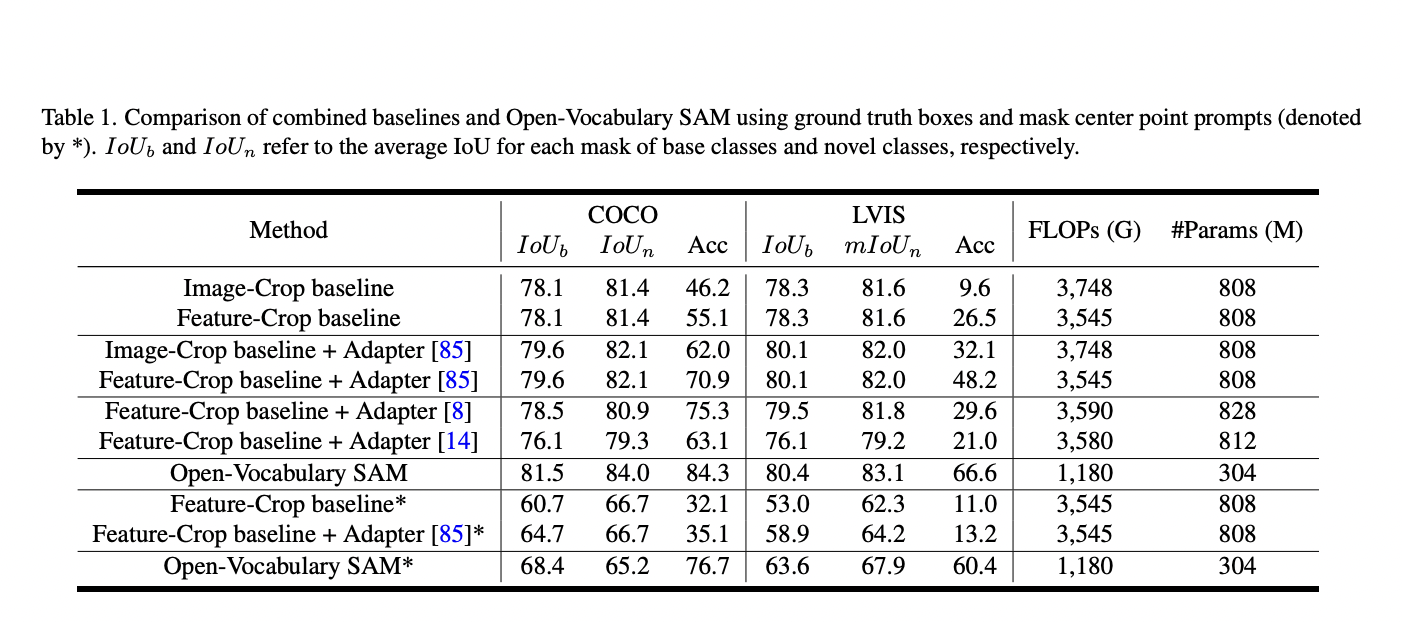
Simplistically merging SAM and CLIP proves to be inefficient. This approach incurs substantial computational expenses and produces suboptimal results, particularly in recognizing small-scale objects. Researchers at Nanyang Technological University delve into the comprehensive integration of these two models into a cohesive framework called the Open-Vocabulary SAM. Inspired by SAM, Open-Vocabulary SAM is meticulously crafted for concurrent interactive segmentation and recognition tasks.
This innovative model harnesses two distinct knowledge transfer modules: SAM2CLIP and CLIP2SAM. SAM2CLIP facilitates adapting SAM’s knowledge into CLIP through distillation and learnable transformer adapters. Conversely, CLIP2SAM transfers CLIP’s knowledge into SAM, augmenting its recognition capabilities.
Extensive experimentation across various datasets and detectors underscores the efficacy of Open-Vocabulary SAM in both segmentation and recognition tasks. Notably, it outperforms naive baselines that involve simply combining SAM and CLIP. Moreover, with the additional advantage of training on image classification data, their method demonstrates the capability to segment and recognize approximately 22,000 classes effectively.
Aligned with SAM’s ethos, researchers bolster their model’s recognition capabilities by leveraging the wealth of knowledge contained in established semantic datasets, including COCO and ImageNet-22k. This strategic utilization elevates their model to the same level of versatility as SAM, providing it with an enhanced ability to segment and recognize diverse objects effectively.
Built upon the foundation of SAM, their approach exhibits flexibility, allowing seamless integration with various detectors. This adaptability makes it well-suited for deployment in both closed-set and open-set environments. To validate the robustness and performance of their model, they conduct extensive experiments across a diverse set of datasets and scenarios. Their experiments encompass closed-set scenarios as well as open-vocabulary interactive segmentation, showcasing the broad applicability and efficacy of their approach.
Check out the Paper, Project, and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.