This AI Paper Introduces VidChapters-7M: A Scalable Approach to Segmenting Videos into Chapters Using User-Annotated Data
In the realm of video content organization, the segmentation of lengthy videos into chapters emerges as an important capability, allowing users to pinpoint their desired information swiftly. Unfortunately, this subject has suffered from hardly any research attention due to the scarcity of publicly available datasets.
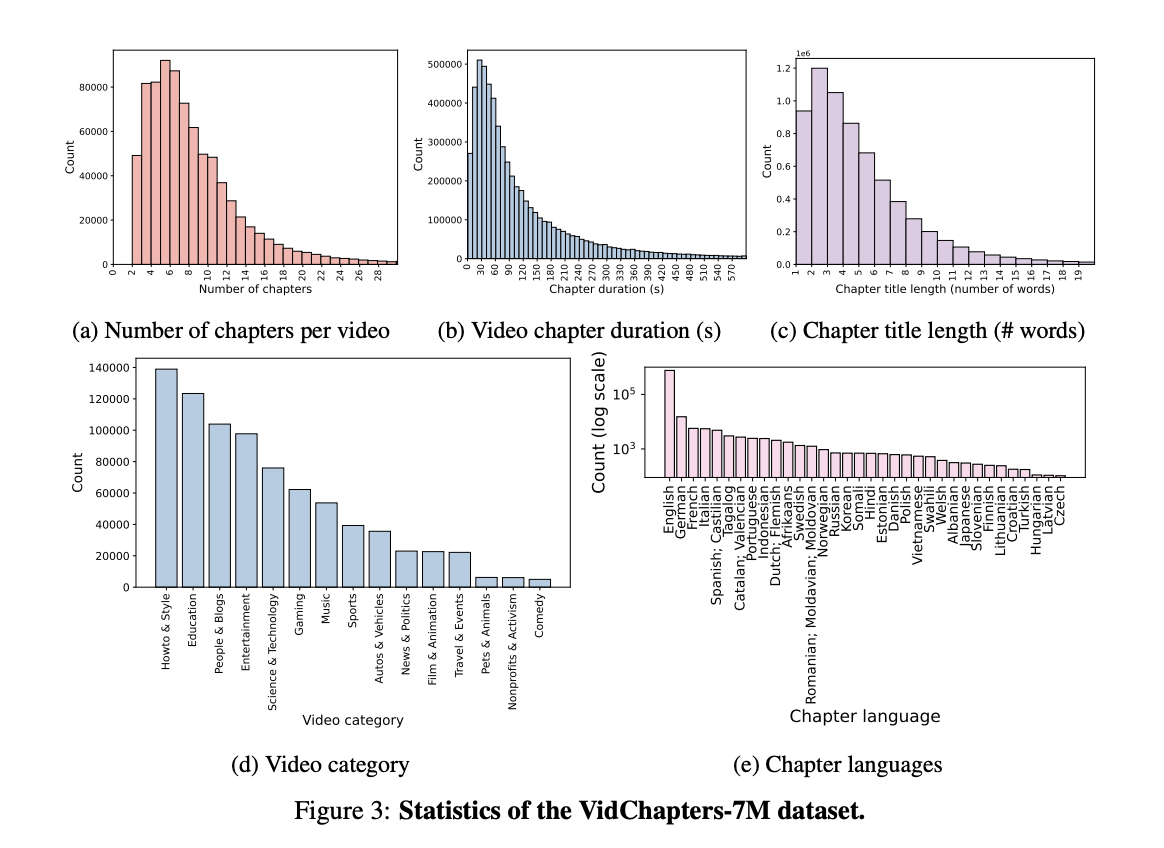
To address this challenge, VidChapters-7M is presented, a dataset comprising 817,000 videos that have been meticulously segmented into an impressive 7 million chapters. This dataset is assembled automatically by extracting user-annotated chapters from online videos, bypassing the need for labor-intensive manual annotation.
Within the scope of VidChapters-7M, researchers have introduced three distinct tasks. Firstly, there is the video chapter generation task, which entails the temporal division of a video into segments, accompanied by the generation of a descriptive title for each segment. To further deconstruct this task, two variations are defined: video chapter generation with predefined segment boundaries, where the challenge lies in generating titles for segments with annotated boundaries, and video chapter grounding, which necessitates the localization of a chapter’s temporal boundaries based on its annotated title.

A comprehensive evaluation of these tasks was conducted that employed both fundamental baseline approaches and cutting-edge video-language models. The above image demonstrates an illustration of the three tasks defined for VidChapters-7M. Furthermore, it has been demonstrated that pre-training on VidChapters-7M results in remarkable advancements in dense video captioning tasks, both in zero-shot and fine-tuning scenarios. This advancement notably elevates the state of the art on benchmark datasets such as YouCook2 and ViTT. Ultimately, the experiments have unveiled a positive correlation between the size of the pretraining dataset and improved performance in downstream applications.
VidChapters-7M inherits certain limitations due to its origin from YT-Temporal-180M. These limitations are associated with the biases in the distribution of video categories that are present in the source dataset. The advancement of video chapter generation models has the potential to facilitate downstream applications, some of which could have negative societal impacts, such as video surveillance.
Additionally, models trained on VidChapters-7M may inadvertently reflect biases that exist within videos sourced from platforms like YouTube. It is necessary to maintain awareness of these considerations when deploying, analyzing, or building upon these models.
Check out the Paper, Github, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.