This AI Paper Proposes a Novel Pre-Training Strategy Called Privacy-Preserving MAE-Align’ to Effectively Combine Synthetic Data and Human-Removed Real Data
Action recognition, the task of identifying and classifying human actions from video sequences, is a crucial field within computer vision. However, its reliance on large-scale datasets containing images of people brings forth significant challenges related to privacy, ethics, and data protection. These issues arise due to the potential identification of individuals based on personal attributes and data collection without explicit consent. Moreover, biases related to gender, race, or specific actions performed by certain groups can affect the accuracy and fairness of models trained on such datasets.
In action recognition, advancements in pre-training methodologies on massive video datasets have been pivotal. However, these advancements come with challenges, such as ethical considerations, privacy issues, and biases inherent in datasets with human imagery. Existing approaches to tackle these issues include blurring faces, downsampling videos, or employing synthetic data for training. Despite these efforts, there needs to be more analysis of how well privacy-preserving pre-trained models transfer their learned representations to downstream tasks. The state-of-the-art models sometimes fail to predict actions accurately due to biases or a lack of diverse representations in the training data. These challenges demand novel approaches that address privacy concerns and enhance the transferability of learned representations to various action recognition tasks.
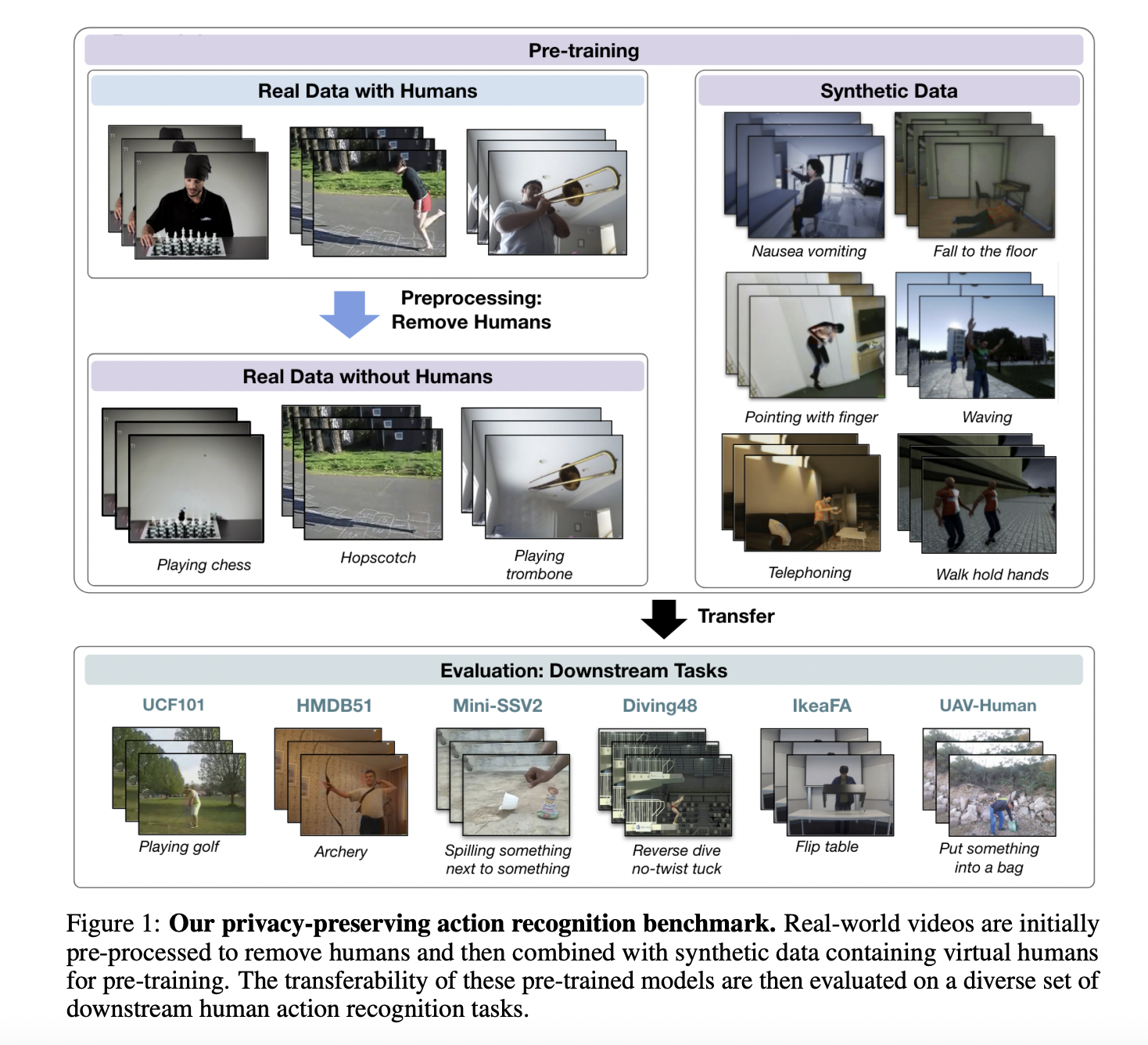
To overcome the challenges posed by privacy concerns and biases in human-centric datasets used for action recognition, a new method was recently presented at NeurIPS 2023, the well-known conference, that introduces a groundbreaking approach. This newly published work devises a methodology to pre-train action recognition models using a combination of synthetic videos containing virtual humans and real-world videos with humans removed. By leveraging this novel pre-training strategy termed Privacy-Preserving MAE-Align (PPMA), the model learns temporal dynamics from synthetic data and contextual features from real videos without humans. This innovative method helps address privacy and ethical concerns related to human data. It significantly improves the transferability of learned representations to diverse downstream action recognition tasks, closing the performance gap between models trained with and without human-centric data.
Concretely, the proposed PPMA method follows these key steps:
- Privacy-Preserving Real Data: The process begins with the Kinetics dataset, from which humans are removed using the HAT framework, resulting in the No-Human Kinetics dataset.
- Synthetic Data Addition: Synthetic videos from SynAPT are included, offering virtual human actions facilitating focus on temporal features.
- Downstream Evaluation: Six diverse tasks evaluate the model’s transferability across various action recognition challenges.
- MAE-Align Pre-training: This two-stage strategy involves:
- Stage 1: MAE Training to predict pixel values, learning real-world contextual features.
- Stage 2: Supervised Alignment using both No-Human Kinetics and synthetic data for action label-based training.
- Privacy-Preserving MAE-Align (PPMA): Combining Stage 1 (MAE trained on No-Human Kinetics) with Stage 2 (alignment using both No-Human Kinetics and synthetic data), PPMA ensures robust representation learning while safeguarding privacy.
The research team conducted experiments to evaluate the proposed approach. Using ViT-B models trained from scratch without ImageNet pre-training, they employed a two-stage process: MAE training for 200 epochs followed by supervised alignment for 50 epochs. Across six diverse tasks, PPMA outperformed other privacy-preserving methods by 2.5% in finetuning (FT) and 5% in linear probing (LP). Although slightly less effective on high scene-object bias tasks, PPMA significantly reduced the performance gap compared to models trained on real human-centric data, showcasing promise in achieving robust representations while preserving privacy. Ablation experiments highlighted the effectiveness of MAE pre-training in learning transferable features, particularly evident when finetuned on downstream tasks. Additionally, exploring the combination of contextual and temporal features, methods like averaging model weights and dynamically learning mixing proportions showed potential for improving representations, opening avenues for further exploration.
This article introduces PPMA, a novel privacy-preserving approach for action recognition models, addressing privacy, ethics, and bias challenges in human-centric datasets. Leveraging synthetic and human-free real-world data, PPMA effectively transfers learned representations to diverse action recognition tasks, minimizing the performance gap between models trained with and without human-centric data. The experiments underscore PPMA’s effectiveness in advancing action recognition while ensuring privacy and mitigating ethical concerns and biases linked to conventional datasets.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Mahmoud is a PhD researcher in machine learning. He also holds a
bachelor’s degree in physical science and a master’s degree in
telecommunications and networking systems. His current areas of
research concern computer vision, stock market prediction and deep
learning. He produced several scientific articles about person re-
identification and the study of the robustness and stability of deep
networks.
Credit: Source link
Comments are closed.