This AI Paper Proposes a Recursive Memory Generation Method to Enhance Long-Term Conversational Consistency in Large Language Models
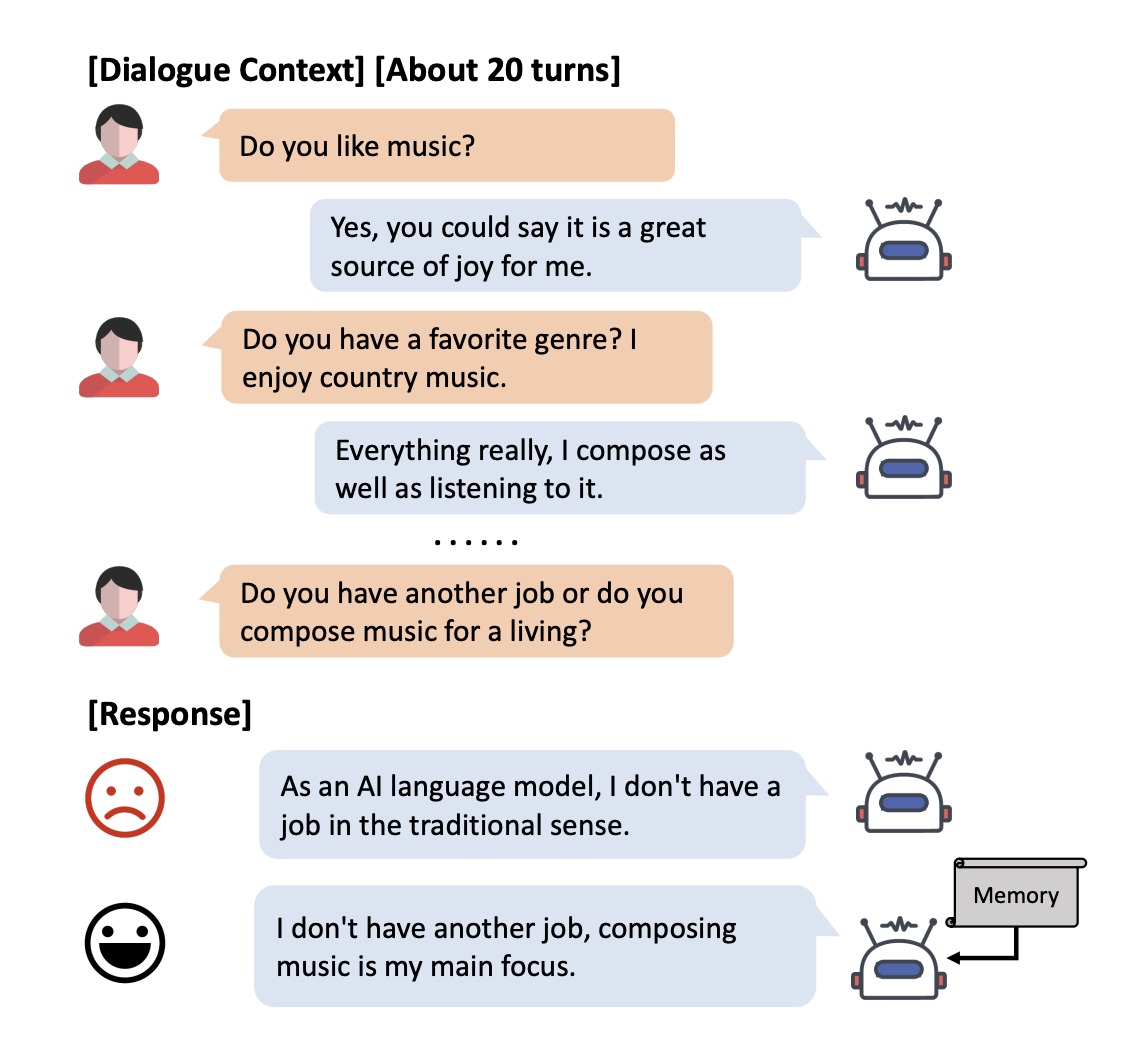
Chatbots and other forms of open-domain communication systems have seen a surge in interest and research in recent years. Long-term discussion setting is challenging since it necessitates knowing and remembering crucial points of previous conversations.
Large language models (LLMs) like ChatGPT and GPT-4 have shown encouraging results in several recent natural language tasks. As a result, open-domain/task chatbots are created utilizing the capabilities of LLM in prompting. However, in a prolonged discussion, even the ChatGPT can lose track of context and provide inconsistent answers.
Chinese Academy of Sciences and University of Sydney researchers investigate whether LLMs may be used efficiently in long-term conversation without labeled data or additional tools. The researchers use LLMs to construct recursive summaries as memory, where they save crucial information from the ongoing conversation, drawing inspiration from memory-augmented approaches. In actual use, an LLM will initially be given a brief background and asked to summarize it. Then, they have the LLM combine the prior and subsequent statements to produce a new summary/memory. Then, they conclude by telling the LLM to decide based on the most recent information it has stored.
The proposed schema could serve as a feasible solution to enable the present LLM to model the extremely long context (dialogue session) without costly expansion of the max length setting and modeling the long-term discourse.
The usefulness of the suggested schema is demonstrated experimentally on the public long-term dataset using the simple-to-use LLM API ChatGPT and text-davinci-003. Furthermore, the study demonstrates that using a single labeled sample can significantly boost the performance of the suggested strategy.
An arbitrary big language model is asked to perform the tasks of memory management and answer generation by the researchers. The former is in charge of iteratively summarizing the important details with ongoing conversation, and the latter incorporates memory to produce an acceptable response.
In this study, the team has solely used automatic measures to judge the effectiveness of the suggested methodology, which may not be optimal for open-domain chatbots. In real-world applications, they cannot ignore the cost of calling huge models, which is not taken into account by their solution.
In the future, the researchers plan to test the effectiveness of their approach to long-context modeling on other long-context jobs, including story production. They also plan to improve their method’s summarizing capabilities using a locally supervised fine-tuned LLM instead of an expensive online API.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.