This AI Paper Proposes A Zero-Shot Personalized Lip2Speech Synthesis Method: A Synthetic Speech Model To Match Lip Movements
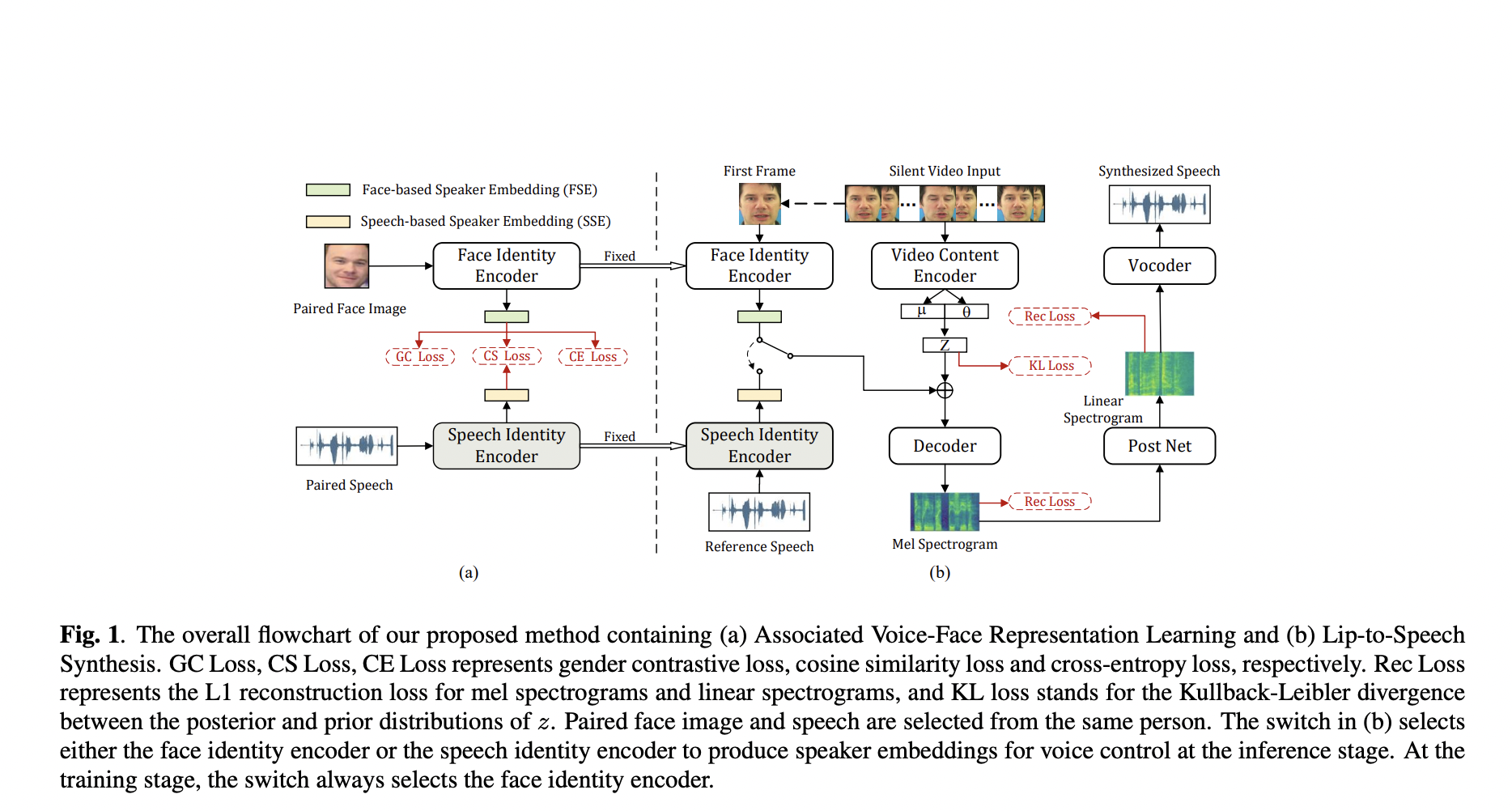
A team of researchers from the University of Science and Technology of China has developed a novel machine-learning model for lip-to-speech (Lip2Speech) synthesis. The model is capable of generating personalized synthesized speech in zero-shot conditions, meaning it can make predictions related to data classes that it did not encounter during training. The researchers introduced their approach leveraging a variational autoencoder—a generative model based on neural networks that encode and decode data.
Lip2Speech synthesis involves predicting spoken words based on the movements of a person’s lips, and it has various real-world applications. For example, it can assist patients who cannot produce speech sounds in communicating with others, add sound to silent movies, restore speech in noisy or damaged videos, and even determine conversations in voice-less CCTV footage. While some machine learning models have shown promise in Lip2Speech applications, they often struggle with real-time performance and are not trained using zero-shot learning approaches.
Typically, to achieve zero-shot Lip2Speech synthesis, machine learning models require reliable video recordings of speakers to extract additional information about their speech patterns. However, in cases where only silent or unintelligible videos of a speaker’s face are available, this information cannot be accessed. The researchers’ model aims to address this limitation by generating speech that matches the appearance and identity of a given speaker without relying on recordings of their actual speech.
The team proposed a zero-shot personalized Lip2Speech synthesis method that utilizes face images to control speaker identities. They employed a variational autoencoder to disentangle speaker identity and linguistic content representations, allowing speaker embeddings to control the voice characteristics of synthetic speech for unseen speakers. Additionally, they introduced associated cross-modal representation learning to enhance the ability of face-based speaker embeddings (FSE) in voice control.
To evaluate the performance of their model, the researchers conducted a series of tests. The results were remarkable, as the model generated synthesized speech that accurately matched a speaker’s lip movements and their age, gender, and overall appearance. The potential applications of this model are extensive, ranging from assistive tools for individuals with speech impairments to video editing software and aid for police investigations. The researchers highlighted the effectiveness of their proposed method through extensive experiments, demonstrating that the synthetic utterances were more natural and aligned with the personality of the input video compared to other methods. Importantly, this work represents the first attempt at zero-shot personalized Lip2Speech synthesis using a face image rather than reference audio to control voice characteristics.
In conclusion, the researchers have developed a machine-learning model for Lip2Speech synthesis that excels in zero-shot conditions. The model can generate personalized synthesized speech that aligns with a speaker’s appearance and identity by leveraging a variational autoencoder and face images. The successful performance of this model opens up possibilities for various practical applications, such as aiding individuals with speech impairments, enhancing video editing tools, and assisting in police investigations.
Check Out The Paper and Reference Article. Don’t forget to join our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.