This AI Paper Proposes an Effective Paradigm for Large Scale Vision-and-Language Navigation (VLN) Training and Quantitatively Evaluates the Influence of Each Component in the Pipeline
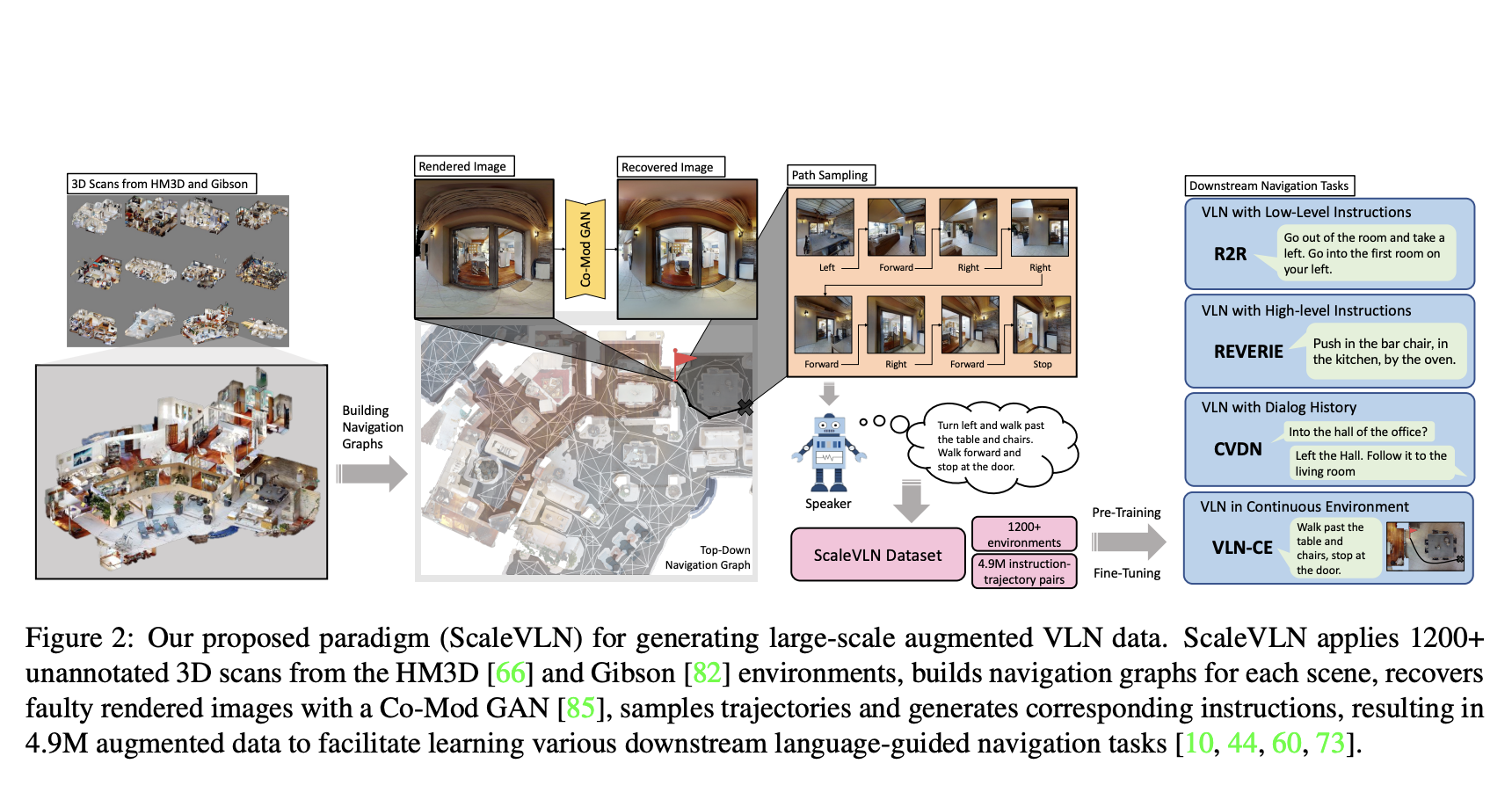
Several human demos have been collected for learning visual navigation, and recent huge datasets contain hundreds of interactive scenarios, both of which have led to significant improvements in agent performance. However, getting to such massive training requires solving a number of key sub-problems, such as how to construct navigation graphs, restore corrupted rendered images, and generate navigational instructions. All of this has a major impact on the quality of the data collected and thus should be thoroughly explored.
It is necessary to research how to efficiently utilize large-scale data to benefit the training of navigational agents appropriately, and an agent that can understand human natural language and navigate in photorealistic surroundings is a sophisticated and modularized system.
To train large-scale vision-and-language navigation networks (VLNs), researchers from the Australian National University, OpenGVLab, Shanghai AI Laboratory, UNC, Chapel Hill, University of Adelaide, and Adobe Research offer a new paradigm by statistically assessing the impact of each component in the pipeline. Using the Habitat simulator, they use environments from the HM3D and Gibson datasets and construct navigation graphs for the environments. They sample new trajectories, create instructions, and train agents to solve downstream navigation problems.
In contrast to prior methods like AutoVLN and MARVAL, these navigation graphs are constructed with an excessive viewpoint sampling and aggregation procedure, employing the graph creation heuristic introduced in. This approach yields fully-connected networks with extensive outdoor coverage.
The researchers also train the Co-Modulated GAN to generate photorealistic images from the broken, deformed, or missing sections in corrupted generated images from HM3D and Gibson settings, reducing visual data noise’s impact. In contrast to MARVAL, this large-scale training regime is fully reproducible and straightforward to execute while significantly improving the agent’s performance.
Extensive experiments show that if the agent is to perform better on downstream tasks with specific instructions, such as R2R, the navigation graph must be fully traversable. Furthermore, they demonstrate the benefits of recovering photorealistic images from generated images, particularly for the low-quality 3D scans from the Gibson habitats. Findings also indicate that agents can generally use more diverse visual data and can improve their generalization to novel contexts by learning from new scenes rather than just more data.
Additionally, the team verifies that an agent trained with augmented instructions provided by a basic LSTM-based model can perform well on various navigation tasks. They conclude that the agent’s generalization capacity can be improved by integrating the augmented data with the original data during pre-training and fine-tuning.
Surprisingly, by using the above analysis as guidelines for data augmentation and agent training, the proposed VLN model can achieve 80% SR on the R2R test split via simple imitation learning without pre-exploration, beam search, or model ensembling and eliminate the navigation gap between seen and unseen environments. This result is a huge improvement over the previous best approach (73%), bringing the performance gap to within 6 percentage points of human levels. The approach to several language-guided visual navigation challenges, such as CVDN and REVERIE, has pushed the state-of-the-art forward. The VLN performance is improved by 5% SR in the continuous environments (R2R-CE), a more realistic yet challenging scenario, even though the enhanced data is discrete.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.