This AI Paper Proposes CaFo: A Cascade of Foundation Models that Incorporates Diverse Prior Knowledge of Various Pre-Training Paradigms for Better Few-Shot Learning
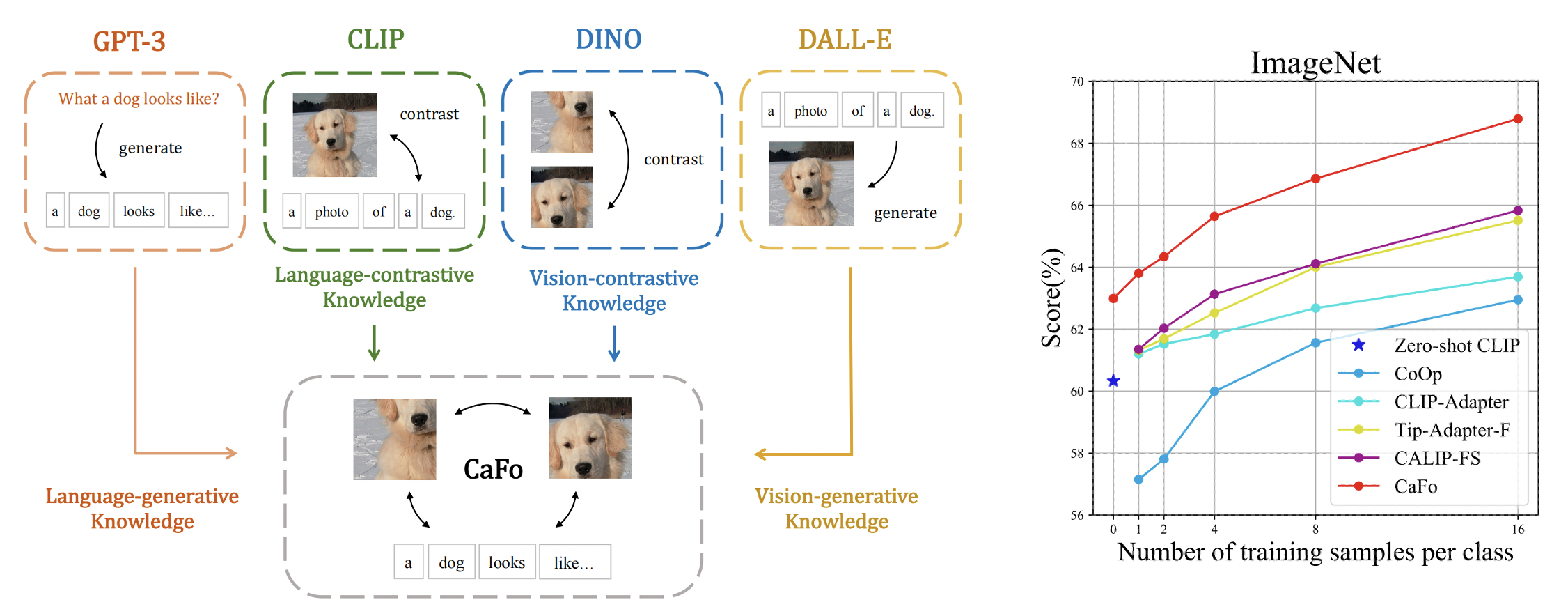
Many datasets, convolutional neural networks, and transformers have achieved remarkable success on various vision tasks. Instead, few-shot learning, where the networks are confined to learn from constrained pictures with annotations, also becomes a research hotspot for various data-deficient and resource-finite scenarios. Numerous earlier publications have suggested using meta-learning, metric learning, and data augmentation to improve a model’s generalization capacity. Recent results demonstrate good zero-shot transfer ability for open-vocabulary visual identification using CLIP pre-trained by large-scale language-image pairings.
It is further extended for few-shot classification by the follow-up CoOp, CLIP-Adapter, and Tip-Adapter, which also achieves improved performance on various downstream datasets. This shows that the network has strong representational capabilities even while the few-shot training material is inadequate, which greatly aids the few-shot learning on downstream domains. With the advent of other self-supervision models than CLIP, may they collaborate and adaptively integrate their prior knowledge to become better few-shot learners? Chinese researchers suggest CaFo, a Cascade of Foundation model, to address this problem by combining the information from several pre-training paradigms with a “Prompt, Produce, then Cache” pipeline.
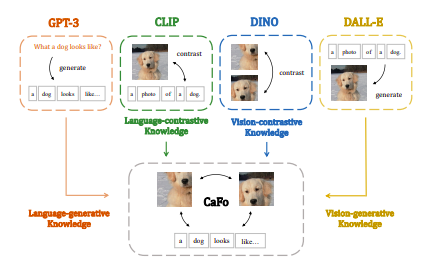
They combine CLIP, DINO, DALL-E, and GPT3 to give CaFo four forms of previous knowledge, as seen in Figure 1. CLIP is pre-trained to provide paired features for each picture and its corresponding description text in the embedding space. With language-contrastive knowledge and texts with various category meanings, CLIP can categorize the photos successfully. DINO uses contrastive self-supervised learning to match the representations between two transformations of the same picture. DINO is an expert at differentiating between various images using vision-contrastive knowledge. DALL-E is pre-trained using picture-text pairings, much like CLIP, except it learns to anticipate the encoded image tokens based on the provided text tokens. Depending on the supplied text, DALLE might use vision-generative knowledge to generate high-quality synthetic pictures in a zero-shot way.
When given a few handwritten templates as input, the large-scale language corpus-trained GPT-3 automatically creates sentences that seem like human speech and are rich in generative language knowledge. The four models, therefore, have different pre-training objectives and might offer to complement information to aid in few-shot visual identification. They cascade them in three phases, specifically:
1) Quick: Based on a few handwritten templates, they use GPT-3 to generate textual prompts for CLIP. The textual encoder in CLIP receives these instructions with a more sophisticated language understanding.
2) Produce: They use DALL-E, which expands the few-shot training data while requiring no more labor for collection and annotation, to produce additional training pictures for various categories based on the domain-specific texts.
3) Cache: To adaptively incorporate the predictions from CLIP and DINO, they use a caching model. They construct the cache model with two types of keys by the two pre-trained models using Tip-Adapter. They adaptively ensemble the predictions of two cached keys as the output, using zero-shot CLIP as the distribution baseline. CaFo can improve few-shot visual recognition by learning to combine previous knowledge and use their complementing properties by fine-tuning the lightweight cache model via increased training data.
The following summarizes their key contributions:
• For improved few-shot learning, they suggest using CaFo to incorporate past information from diverse pre-training paradigms.
• They conduct thorough experiments on 11 datasets for few-shot classification, where CaFo achieves state-of-the-art without using additional annotated data.
• They collaborate with CLIP, DINO, GPT-3, and DALL-E to use more semantic prompts, enrich the limited few-shot training data, and adaptively ensemble diverse predictions via the cache model.
Check out the Paper and Code. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.