This AI Paper Proposes COLT5: A New Model For Long-Range Inputs That Employs Conditional Computation For Higher Quality And Faster Speed
Machine learning models are needed to encode long-form text for various natural language processing tasks, including summarising or answering questions about lengthy documents. Since attention cost rises quadratically with input length and feedforward and projection layers must be applied to each input token, processing long texts using a Transformer model is computationally costly. Several “efficient Transformer” strategies have been put out in recent years that lower the expense of the attention mechanism for lengthy inputs. Nevertheless, the feedforward and projection layers—particularly for bigger models—carry the bulk of the computing load and can make it impossible to analyze lengthy inputs. This study introduces COLT5, a new family of models that, by integrating architecture enhancements for both attention and feedforward layers, build on LONGT5 to enable quick processing of lengthy inputs.
The foundation of COLT5 is the understanding that certain tokens are more significant than others and that by allocating more compute to important tokens, higher quality may be obtained at a reduced cost. For example, COLT5 separates each feedforward layer and each attention layer into a light branch applied to all tokens and a heavy branch used for selecting significant tokens chosen especially for that input and component. Compared to regular LONGT5, the hidden dimension of the light feedforward branch is smaller than that of the heavy feedforward branch. Also, the percentage of significant tokens will decrease with document length, enabling manageable processing of lengthy texts.
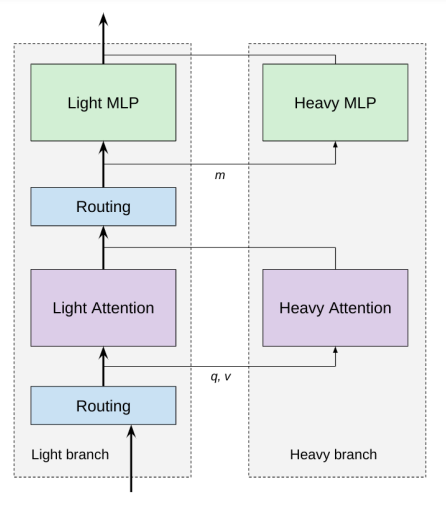
An overview of the COLT5 conditional mechanism is shown in Figure 1. The LONGT5 architecture has undergone two further changes thanks to COLT5. The heavy attention branch performs complete attention across a different set of carefully chosen significant tokens, whereas the light attention branch has fewer heads and applies local attention. Multi-query cross-attention, which COLT5 introduces, dramatically accelerates inference. Moreover, COLT5 uses the UL2 pre-training target, which they show enables in-context learning across lengthy inputs.
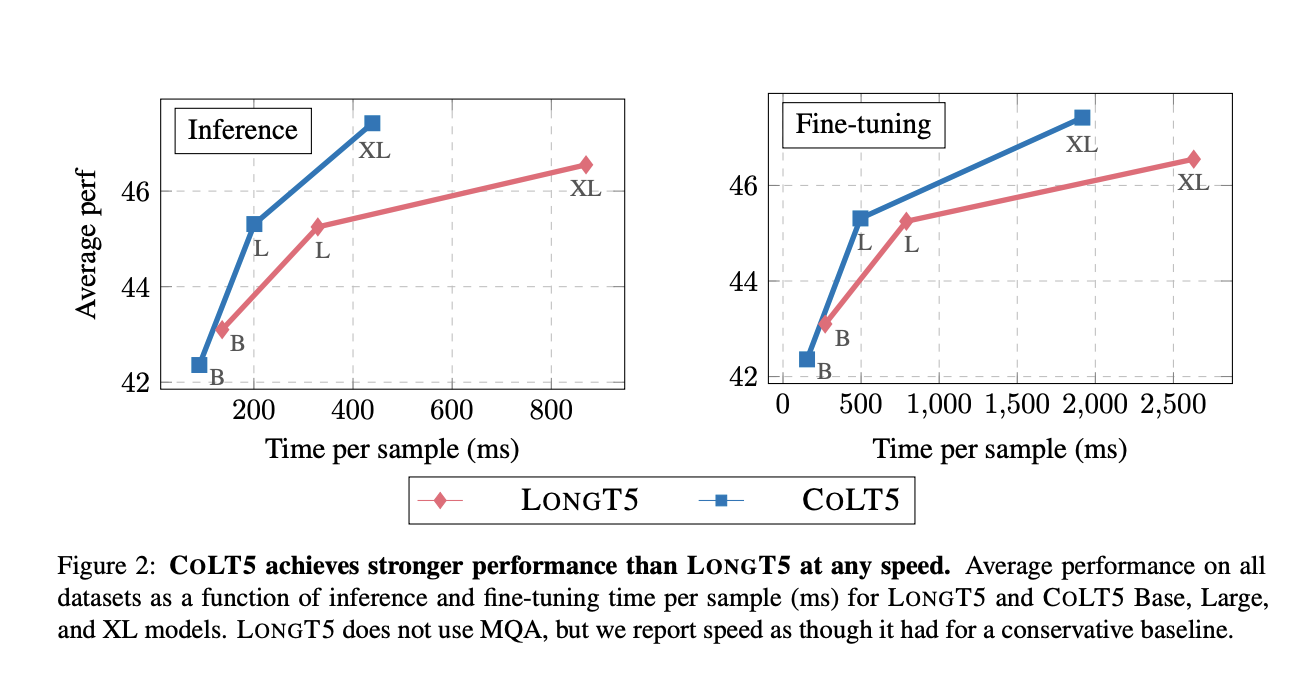
Researchers from Google Research suggest COLT5, a fresh model for distant inputs that use conditional computing for better performance and quicker processing. They demonstrate that COLT5 outperforms LONGT5 on the arXiv summarization and TriviaQA question-answering datasets, improving over LONGT5 and reaching SOTA on the SCROLLS benchmark. With less-than-linear scaling of “focus” tokens, COLT5 considerably enhances quality and performance for jobs with lengthy inputs. COLT5 also performs substantially quicker finetuning and inference with the same or superior model quality. Light feedforward and attention layers in COLT5 apply to all of the input, whereas heavy branches only affect a selection of significant tokens chosen by a learned router. They demonstrate that COLT5 outperforms LONGT5 on various long-input datasets at all speeds and can successfully and efficiently employ extremely long inputs up to 64k tokens.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.