This AI Paper Proposes FACTORCL: A New Multimodal Representation Learning Method to Go Beyond Multi-View Redundancy
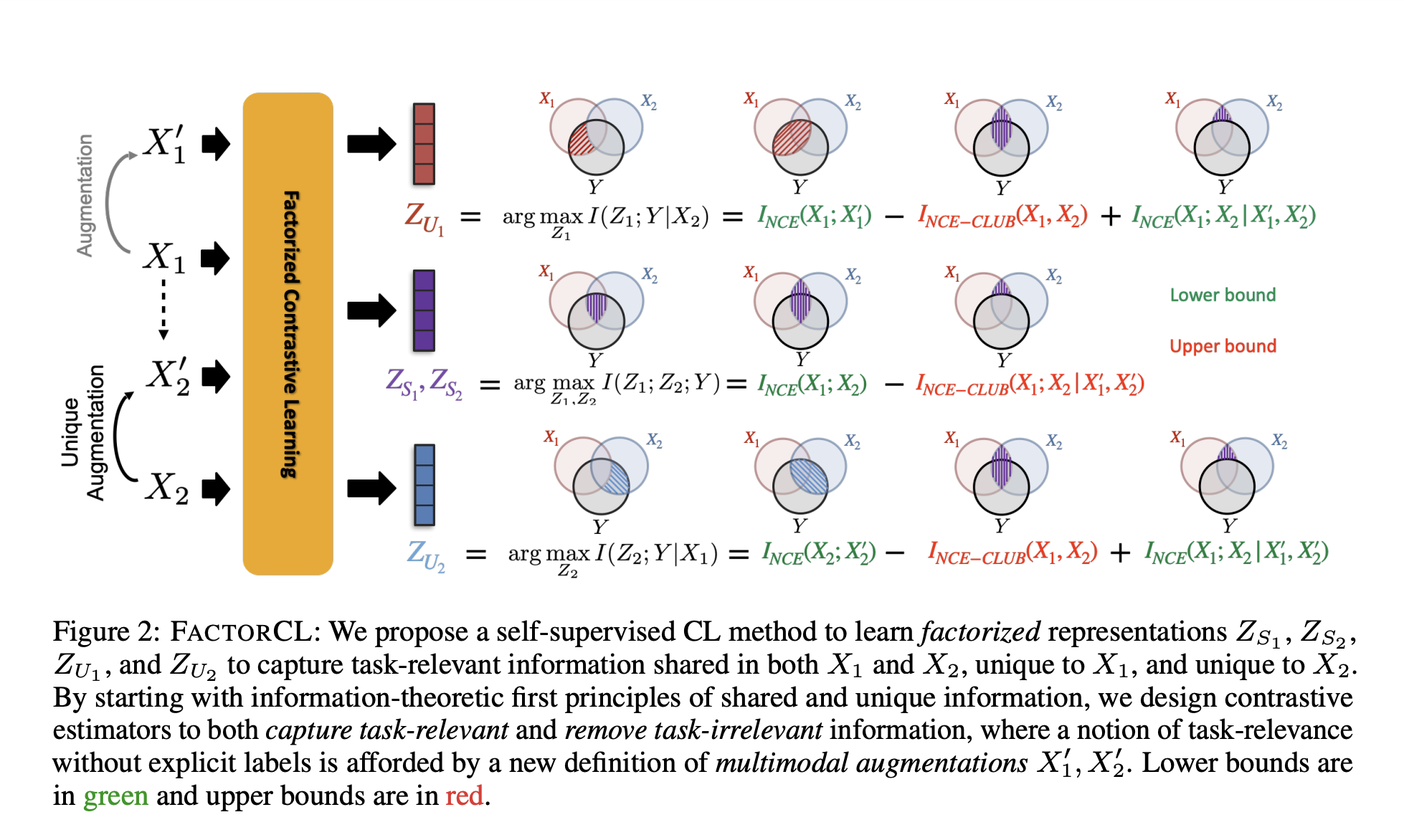
One of the main paradigms in machine learning is learning representations from several modalities. Pre-training broad pictures on unlabeled multimodal data and then fine-tuning ask-specific labels is a common learning strategy today. The present multimodal pretraining techniques are mostly derived from earlier research in multi-view learning, which capitalizes on a crucial premise of multi-view redundancy: the characteristic that information exchanged throughout modalities is nearly entirely pertinent for tasks that come after. Assuming this is true, approaches that use contrastive pretraining to capture shared data and then fine-tune to retain task-relevant shared information have been successfully applied to learning from speech and transcribed text, images and captions, video and audio, instructions, and actions.
Nevertheless, their study examines two key restrictions on the use of contrastive learning (CL) in more extensive real-world multimodal contexts:
1. Low sharing of task-relevant information Many multimodal tasks with little shared information exist, such those between cartoon pictures and figurative captions (i.e., descriptions of the visuals that are metaphorical or idiomatic rather than literal). Under these conditions, traditional multimodal CLs will find it difficult to acquire the required task-relevant information and will only learn a small portion of the taught representations.
2. Highly distinctive data pertinent to tasks: Numerous modalities might offer distinct information that isn’t found in other modalities. Robotics utilizing force sensors and healthcare with medical sensors are two examples.
Task-relevant unique details will be ignored by standard CL, which will result in subpar downstream performance. How can they create appropriate multimodal learning objectives beyond multi-view redundancy in light of these constraints? Researchers from Carnegie Mellon University, University of Pennsylvania and Stanford University in this paper begin with the fundamentals of information theory and present a method called FACTORIZED CONTRASTIVE LEARNING (FACTORCL) to learn these multimodal representations beyond multi-view redundancy. It formally defines shared and unique information through conditional mutual statements.
First, factorizing common and unique representations explicitly is the concept. To create representations with the appropriate and necessary amount of information content, the second approach is to maximize lower bounds on MI to obtain task-relevant information and minimize upper bounds on MI to extract task-irrelevant information. Ultimately, using multimodal augmentations establishes task relevance in the self-supervised scenario without explicit labeling. Using a variety of synthetic datasets and extensive real-world multimodal benchmarks involving images and figurative language, they experimentally assess the efficacy of FACTORCL in predicting human sentiment, emotions, humor, and sarcasm, as well as patient disease and mortality prediction from health indicators and sensor readings. On six datasets, they achieve new state-of-the-art performance.
The following enumerates their principal technological contributions:
1. A recent investigation of contrastive learning performance demonstrates that, in low shared or high unique information scenarios, typical multimodal CL cannot collect task-relevant unique information.
2. FACTORCL is a brand-new contrastive learning algorithm:
(A) To improve contrastive learning for handling low shared or high unique information, FACTORCL factorizes task-relevant information into shared and unique information.
(B) FACTORCL optimizes shared and unique information independently, producing optimum task-relevant representations by capturing task-relevant information via lower limits and eliminating task-irrelevant information using MI upper bounds.
(C) Using multimodal augmentations to estimate task-relevant information, FACTORCL allows for self-supervised learning from the FACTORCL they developed.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.