This AI Paper Proposes LLM-Grounder: A Zero-Shot, Open-Vocabulary Approach to 3D Visual Grounding for Next-Gen Household Robots
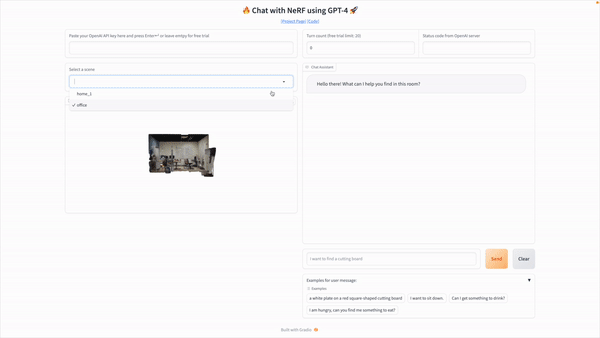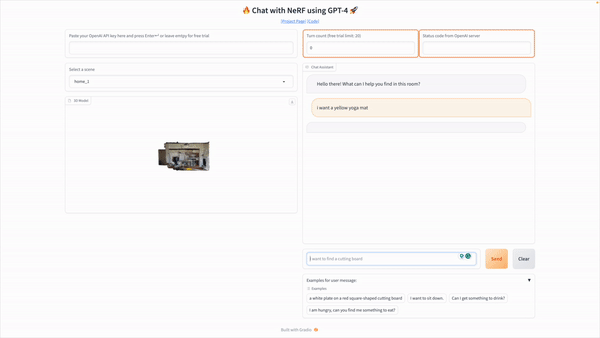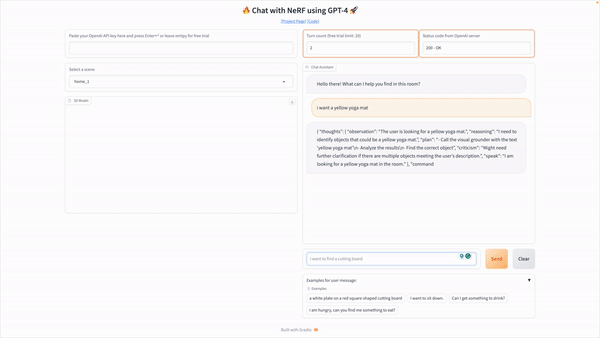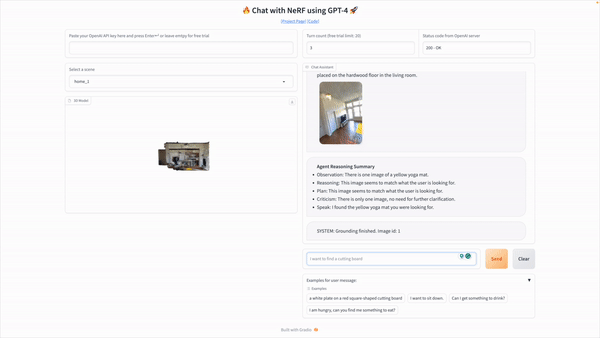
Understanding their surroundings in three dimensions (3D vision) is essential for domestic robots to perform tasks like navigation, manipulation, and answering queries. At the same time, current methods can need help to deal with complicated language queries or rely excessively on large amounts of labeled data.
ChatGPT and GPT-4 are just two examples of large language models (LLMs) with amazing language understanding skills, such as planning and tool use. By breaking down large problems into smaller ones and learning when, what, and how to employ a tool to finish sub-tasks, LLMs can be deployed as agents to solve complicated problems. Parsing the compositional language into smaller semantic constituents, interacting with tools and environment to collect feedback, and reasoning with spatial and commonsense knowledge to iteratively ground the language to the target object are all necessary for 3D visual grounding with complex natural language queries.
Nikhil Madaan and researchers from the University of Michigan and New York University present LLM-Grounder, a novel zero-shot LLM-agent-based 3D visual grounding process that uses an open vocabulary. While a visual grounder excels at grounding basic noun phrases, the team hypothesizes that an LLM can help mitigate the “bag-of-words” limitation of a CLIP-based visual grounder by taking on the challenging language deconstruction, spatial, and commonsense reasoning tasks itself.
LLM-Grounder relies on an LLM to coordinate the grounding procedure. After receiving a natural language query, the LLM breaks it down into its parts or semantic ideas, such as the type of object sought, its properties (including color, shape, and material), landmarks, and geographical relationships. To locate each concept in the scene, these sub-queries are sent to a visual grounder tool supported by OpenScene or LERF, both of which are CLIP-based open-vocabulary 3D visual grounding approaches. The visual grounder suggests a few bounding boxes based on where the most promising candidates for a notion are located in the scene. The visual grounder tools compute spatial information, such as object volumes and distances to landmarks, and feed that data back to the LLM agent, allowing the latter to make a more well-rounded assessment of the situation in terms of spatial relation and common sense and ultimately choose a candidate that best matches all criteria in the original query. The LLM agent will continue to cycle through these steps until it reaches a decision. The researchers take a step beyond existing neural-symbolic methods by using the surrounding context in their analysis.
The team highlights that the method doesn’t require labeled data for training. Given the semantic variety of 3D settings and the scarcity of 3D-text labeled data, its open-vocabulary and zero-shot generalization to novel 3D scenes and arbitrary text queries is an attractive feature. Using the ScanRefer benchmark, the researchers conduct experimental evaluations of LLM-Grounder. The ability to interpret compositional visual referential expressions is important to evaluating grounding in 3D vision language in this benchmark. The results show that the method outperforms state-of-the-art zero-shot grounding accuracy on ScanRefer with no labeled data. It also enhances the grounding capacity of open-vocabulary approaches like OpenScene and LERF. Based on their erasure research, LLM improves grounding capabilities in proportion to the complexity of the language query. These show the efficiency of the LLM-Grounder method for 3D vision language problems, making it ideal for robotics applications where awareness of context and the ability to quickly and accurately react to changing questions are crucial.
Check out the Paper and Demo. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.