This AI Paper Proposes MoE-Mamba: Revolutionizing Machine Learning with Advanced State Space Models and Mixture of Experts MoEs Outperforming both Mamba and Transformer-MoE Individually
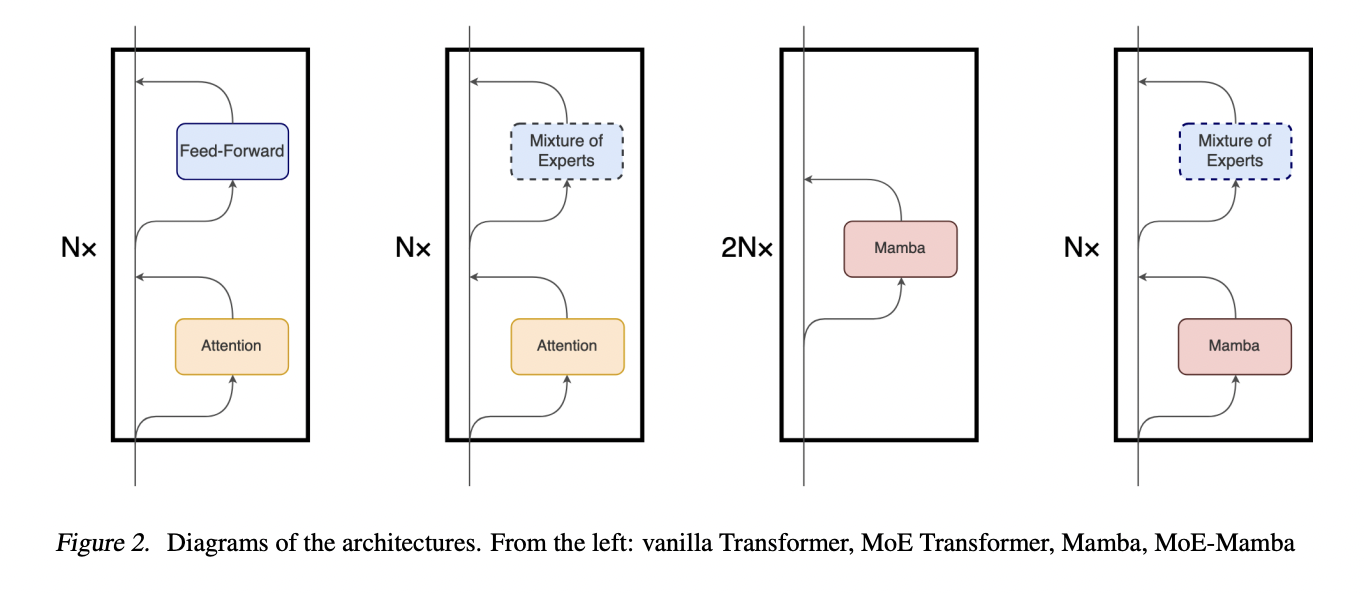
State Space Models (SSMs) and Transformers have emerged as pivotal components in sequential modeling. The challenge lies in optimizing the scalability of SSMs, which have shown promising potential but are yet to surpass the dominance of Transformers. This research addresses the need to enhance the scaling capabilities of SSMs by proposing a fusion with a Mixture of Experts (MoE). The overarching problem centers on optimizing sequential modeling efficiency compared to established models like Transformers.
SSMs have gained attention as a family of architectures, blending the characteristics of RNNs and CNNs, rooted in control theory. Recent breakthroughs have facilitated the scaling of deep SSMs to billions of parameters, ensuring computational efficiency and robust performance. Mamba, an extension of SSMs, introduces linear-time inference and hardware-aware design, mitigating the impact of sequential recurrence. The innovative approach to state compression and a selective information propagation mechanism makes Mamba a promising sequence modeling backbone, rivaling or surpassing established Transformer models across diverse domains.
A team of researchers has proposed combining MoE with SSMs to unlock the potential of SSMs for scaling up. The model developed, MoE-Mamba, combines Mamba with a MoE layer and achieves remarkable performance, outperforming Mamba and Transformer-MoE. It reaches the same performance as Mamba in 2.2x less training steps while preserving the inference performance gains of Mamba against the Transformer. The preliminary results indicate a promising research direction that may allow scaling SSMs to tens of billions of parameters.
The research extends beyond the fusion of MoE with SSMs and delves into enhancing the Mamba architecture. A pivotal aspect is the exploration of conditional computation in Mamba’s block design. This modification is anticipated to enhance the overall architecture, creating a need for further investigation into the synergies between conditional computation and MoE within SSMs, facilitating more efficient scaling to larger language models.
While it is the case that the integration of MoE into the Mamba layer shows promising results, especially when using a performant sparse MoE feed-forward layer, one of the limitations to note is that in the case of a dense setting, Mamba performs slightly better without the feed-forward layer.
In summary, this research introduces MoE-Mamba, a model born from the integration of MoE with the Mamba architecture. MoE-Mamba surpasses both Mamba and Transformer-MoE, achieving parity with Mamba in 2.2x fewer training steps while maintaining Mamba’s inference superiority over the Transformer. It emphasizesthe potential of combining MoE with SSMs for scaling, this work envisions more efficient scaling to larger language models. The authors anticipate that this study will serve as a catalyst, inspiring further exploration into the synergy of conditional computation, especially MoE, with SSMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link
Comments are closed.