This AI Paper Proposes Retentive Networks (RetNet) as a Foundation Architecture for Large Language Models: Achieving Training Parallelism, Low-Cost Inference, and Good Performance
Transformer, which was first developed to address the sequential training problem with recurrent models, has since come to be accepted as the de facto architecture for big language models. Transformers’ O(N) complexity per step and memory-bound key-value cache make it unsuitable for deployment, trade-off training parallelism for poor inference. The sequence’s lengthening slows inference speed, increases latency, and uses more GPU memory. The next-generation architecture has continued extensive development to maintain training parallelism and competitive performance as Transformers while having effective O(1) inference.

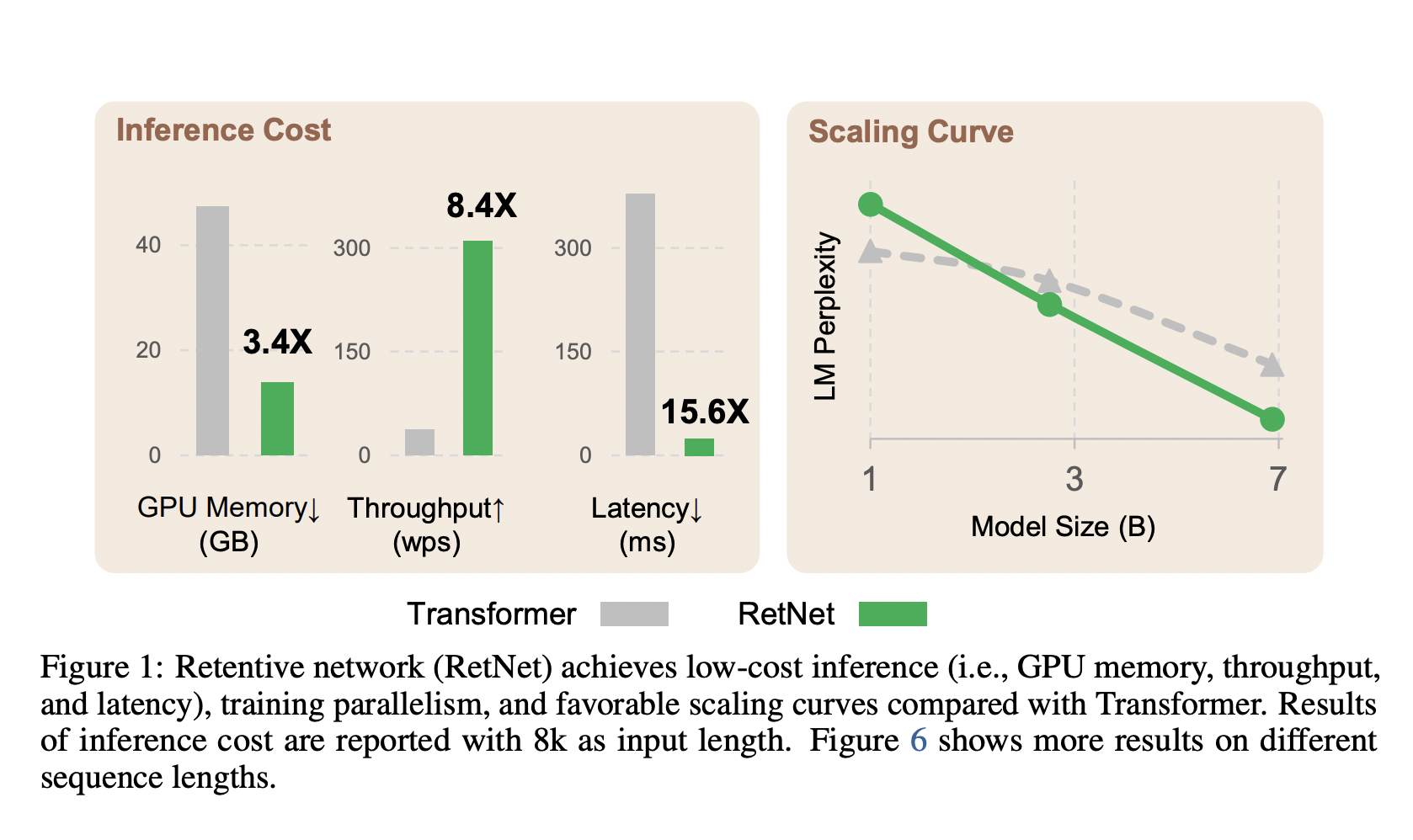
The so-called “impossible triangle” in Figure 1 illustrates how difficult it is to accomplish the objectives mentioned above simultaneously. Three key research streams have been present. To rewrite autoregressive inference in a recurrent form, linearized attention first approximates conventional attention scores exp(q . k) using kernels ϕ(q). ϕ(k). The method’s popularity could be improved because it performs and models less well than Transformers. The second strand forgoes parallel training in favor of recurrent models for effective inference. Element-wise operators are employed to fix acceleration, although this compromises representation capacity and performance. For attention, the third line of inquiry investigates substituting alternative mechanisms, such as S4 and its variations.
There is no apparent winner compared to Transformers since none of the earlier works can escape the impasse. Researchers from Microsoft Research and Tsinghua University propose retentive networks (RetNet) which concurrently provide low-cost inference, effective long-sequence modeling, Transformer-comparable performance, and parallel model training. They specifically offer a multi-scale retention mechanism with three processing paradigms, similar, recurrent, and chunkwise recurrent representations, to replace multi-head attention. First, training parallelism may fully utilize GPU devices thanks to the parallel representation. Second, the recurrent representation makes efficient O(1) inference in terms of memory and computation possible. Both the deployment expense and latency may be greatly decreased.
Without key-value cache techniques, the method is also far more straightforward. Third, effective long-sequence modeling may be done using the chunkwise recurrent representation. They repeatedly encode the global blocks to conserve GPU memory while simultaneously encoding each local block to speed up processing. To compare RetNet with Transformer and its derivatives, they do comprehensive trials. According to experimental results on language modeling, RetNet constantly competes in terms of scaling curves and in-context learning. Additionally, RetNet’s inference cost is length-invariant.
RetNet decodes 8.4 times quicker and uses 70% less memory than Transformers with key-value caches for a 7B model and an 8k sequence length. RetNet also saves 25–50% more memory while training accelerates compared to a normal Transformer and performs better than highly optimized FlashAttention. RetNet’s inference latency is unaffected by the batch size, enabling extremely high throughput. RetNet is a strong Transformer replacement for big language models because of its fascinating features.
Check out the Paper and Github link. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.