This AI Paper Proposes UPRISE: A Lightweight and Versatile Approach to Improve the Zero-Shot Performance of Different Large Language Models LLMs on Various Tasks
Large language models like GPT-3, OPT, and BLOOM have demonstrated impressive capabilities in various applications. According to a recent study, there are two key ways to boost their performance: improving LLMs’ ability to follow prompts and creating procedures for prompt engineering. Fine-tuning LLMs alters their weights to meet specific instructions and increase task performance. This could be constrained, though, by processing resources and the unavailability of model weights. A different method for enhancing zero-shot task generalization is provided by multi-task tuning, which partially justifies the expense of tuning.
Yet, because LLMs are always evolving, it becomes necessary to fine-tune new models, which raises serious questions about the total cost of fine-tuning. Engineering cues are used to direct frozen LLMs. The prompt design incorporates an engineering natural language prompt into the task input to train the LLM to learn in context or to encourage the LLM to reason. Quick tuning adds a soft prompt represented by continuous parameters to improve it. Although these techniques can provide outstanding results for particular jobs, it is unclear if prompts created for one task can be used for other task types that have not yet been discovered since tight zero-shot settings make prompt designers blind.
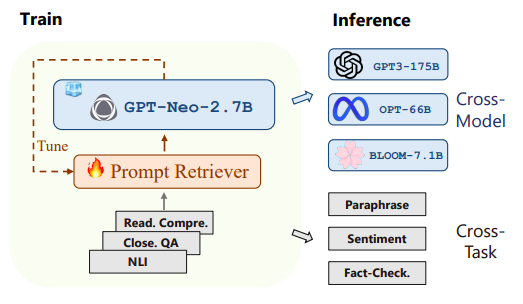
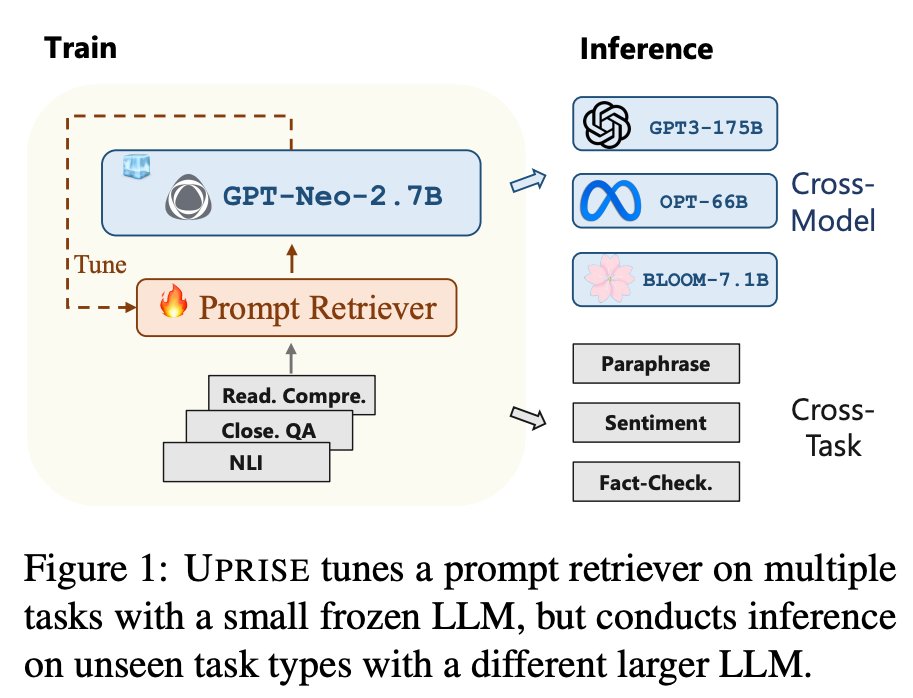
UPRISE proposed by Microsoft researchers is a viable and useful solution for real-world applications because of its cross-model and cross-task generalization. In this study, they offer UPRISE, a lightweight and adaptable retriever that, given a zero-shot job input, adjusts prompts from a pre-constructed pool of data automatically. The retriever is taught to recover cues for various tasks, as seen in Figure 1, allowing it to generalize to other task types during inference. Moreover, they show how effectively the cross-task skills translate from a tiny LLM to several LLMs of considerably larger scales by tweaking the retriever using GPT-Neo-2.7B and assessing its performance on BLOOM-7.1B, OPT-66B, and GPT3-175B.
ChatGPT has been discovered to struggle with major hallucination issues, resulting in factually incorrect replies despite its great skills. UPRISE can solve this problem for fact-checking tasks by instructing the model to deduce the right conclusions from its pre-existing knowledge. Additionally, as demonstrated by their trials with ChatGPT, their technique can improve even the most potent LLMs.
In conclusion, their contributions include the following:
• They develop UPRISE, a simple and adaptable method to enhance LLMs’ zero-shot performance in cross-task and cross-model contexts.
• Their investigation on ChatGPT reveals the potential of UPRISE in boosting the performance of even the strongest LLMs. UPRISE is adjusted with GPT-Neo-2.7B but can also benefit various LLMs of considerably bigger sizes, such as BLOOM-7.1B, OPT-66B, and GPT3-175B.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.