This AI Paper Provides a Comprehensive Overview and Discussion of Various Types of Leakage in Machine Learning Pipelines
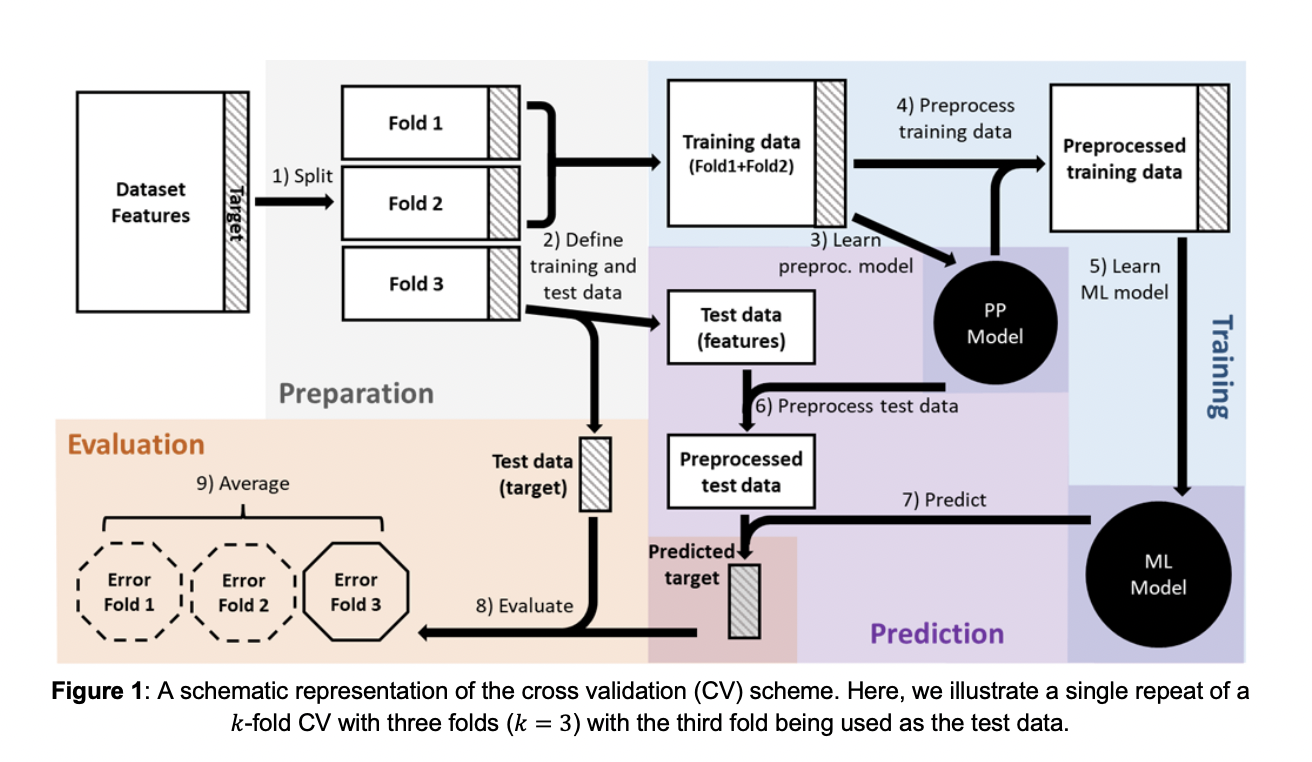
Machine learning (ML) has substantially transformed fields like medicine, physics, meteorology, and climate analysis by empowering predictive modeling, decision support, and insightful data interpretation. The prevalence of user-friendly software libraries featuring a plethora of learning algorithms and data manipulation tools has drastically reduced the learning curve in ML-based studies, fostering the growth of ML-based software. While these tools offer ease of use, constructing a tailored ML-based data analysis pipeline remains challenging, necessitating customization for specific requirements in data, preprocessing, feature engineering, parameter optimization, and model selection.
Even seemingly simple ML pipelines can lead to catastrophic outcomes when incorrectly constructed or interpreted. Therefore, it’s pivotal to highlight that repeatability in an ML pipeline does not guarantee accurate inferences. Addressing these issues is crucial for enhancing applications and fostering social acceptance of ML methodologies.
This discussion particularly focuses on supervised learning, a subset of ML wherein users work with data presented as feature-target pairs. While numerous techniques and AutoML have democratized the construction of high-quality models, it’s essential to note the scope of this work’s limitations. An overarching challenge in ML, data leakage, significantly impacts the reliability of models. Detecting and preventing leakage is vital to ensure model accuracy and trustworthiness. The text provides comprehensive examples, detailed descriptions of data leakage incidents, and guidance on identification.
A collective study presents some crucial points underlying most leakage cases. This study was conducted by researchers from the Institute of Neuroscience and Medicine, Institute of Systems Neuroscience, Heinrich-Heine-University Düsseldorf, Max Planck School of Cognition, University Hospital Ulm, University Ulm, Principal Global Services (India), University College London, London, The Alan Turing Institute, European Lab for Learning & Intelligent Systems (ELLIS) and IIT Bombay. Key strategies to prevent data leakage include:
- Strict separation of training and testing data.
- Utilizing nested cross-validation for model evaluation.
- Defining the end goal of the ML pipeline.
- Rigorous testing for feature availability post-deployment.
The team highlights that maintaining transparency in pipeline design, sharing techniques, and making code accessible to the public can enhance confidence in a model’s generalizability. Additionally, leveraging existing high-quality software and libraries is encouraged while maintaining the integrity of an ML pipeline takes precedence over its output or reproducibility.
Recognizing that data leakage isn’t the sole challenge in ML, the text acknowledges other potential issues, such as dataset biases, deployment difficulties, and the relevance of benchmark data in real-world scenarios. While these aspects couldn’t all be encompassed in this discussion, readers are cautioned to remain vigilant about potential issues in their analysis methods.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.