This AI Paper Unveils DiffEnc: Advancing Diffusion Models for Enhanced Generative Performance
Diffusion models are powerful models that are prominent in a diverse range of generation tasks – images, speech, video, and music. They are able to achieve state-of-the-art performance in image generation, with superior visual quality and density estimation. Diffusion models define a Markov Chain of diffusion steps to gradually add random noise to the images and then learn to reverse the process to generate desired high-quality images.
Diffusion models operate as a hierarchical framework, with a series of latent variables generated sequentially, where each variable depends on the one generated in the previous step. The architecture of diffusion models has the following constraints:
- The process of introducing noise into the data is straightforward and fixed.
- Each layer of hidden variables is dependent only on the previous step.
- All the steps in the model share the same parameters.
Despite the restrictions mentioned above, diffusion models are highly scalable and flexible. In this paper, a group of researchers have introduced a new framework, DiffEnf, to further increase the flexibility without affecting their scalability.
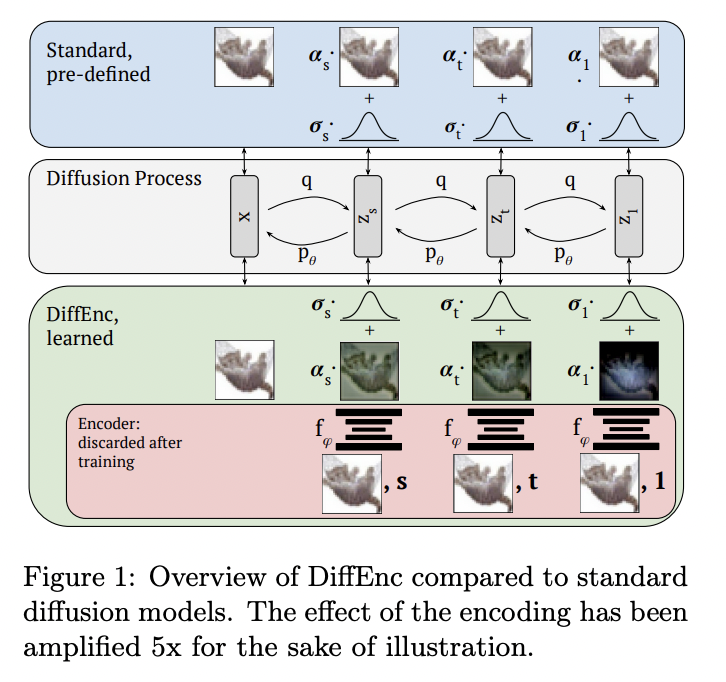
Differing from the traditional method of adding noise, the researchers have introduced a time-dependent encoder that parameterizes the mean of the diffusion process. The encoder essentially predicts the encoded image at a given time. Moreover, this encoder is used solely at the training phase and not during the sampling process. These two properties make DiffEnc more flexible than traditional diffusion models without affecting the sampling time.
For evaluation, the researchers compared different versions of DiffEnc with a standard VDM baseline on two popular datasets: CIFAR-10 and MNIST. The DiffEnc-32-4 model outperforms the previous works and the VDMv-32 model in terms of lower Bits Per Dimension (BPD). This suggests that the encoder, although not used during sampling, contributes to a better generative model without affecting the sampling time. The results also show that the difference in the total loss is primarily due to the improvement in the diffusion loss for DiffEnc-32-4, emphasizing the helpful role of the encoder in the diffusion process.
The researchers also observed that increasing the size of the encoder does not result in a significant improvement in the average diffusion loss as compared to VDM. They hypothesize that in order to achieve significant differences, longer training may be required, or a larger diffusion model might be necessary to fully utilize the encoder’s capabilities.
The results show that adding a time-dependent encoder could improve the diffusion process. Even though the encoder does not increase the sampling time, the sampling process is still slower compared to Generative Adversarial Networks (GANs). Nevertheless, despite this limitation, DiffEnc still improves the flexibility of diffusion models and is able to achieve state-of-the-art likelihood on the CIFAR-10 dataset. Moreover, the researchers propose that the framework could be combined with other existing methods, such as latent diffusion, discriminator guidance, and consistency regularization, to improve the learned representations, potentially opening up new avenues for a wide range of image generation tasks.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various areas.
Credit: Source link
Comments are closed.