This AI Paper Unveils REVEAL: A Groundbreaking Dataset for Benchmarking the Verification of Complex Reasoning in Language Models
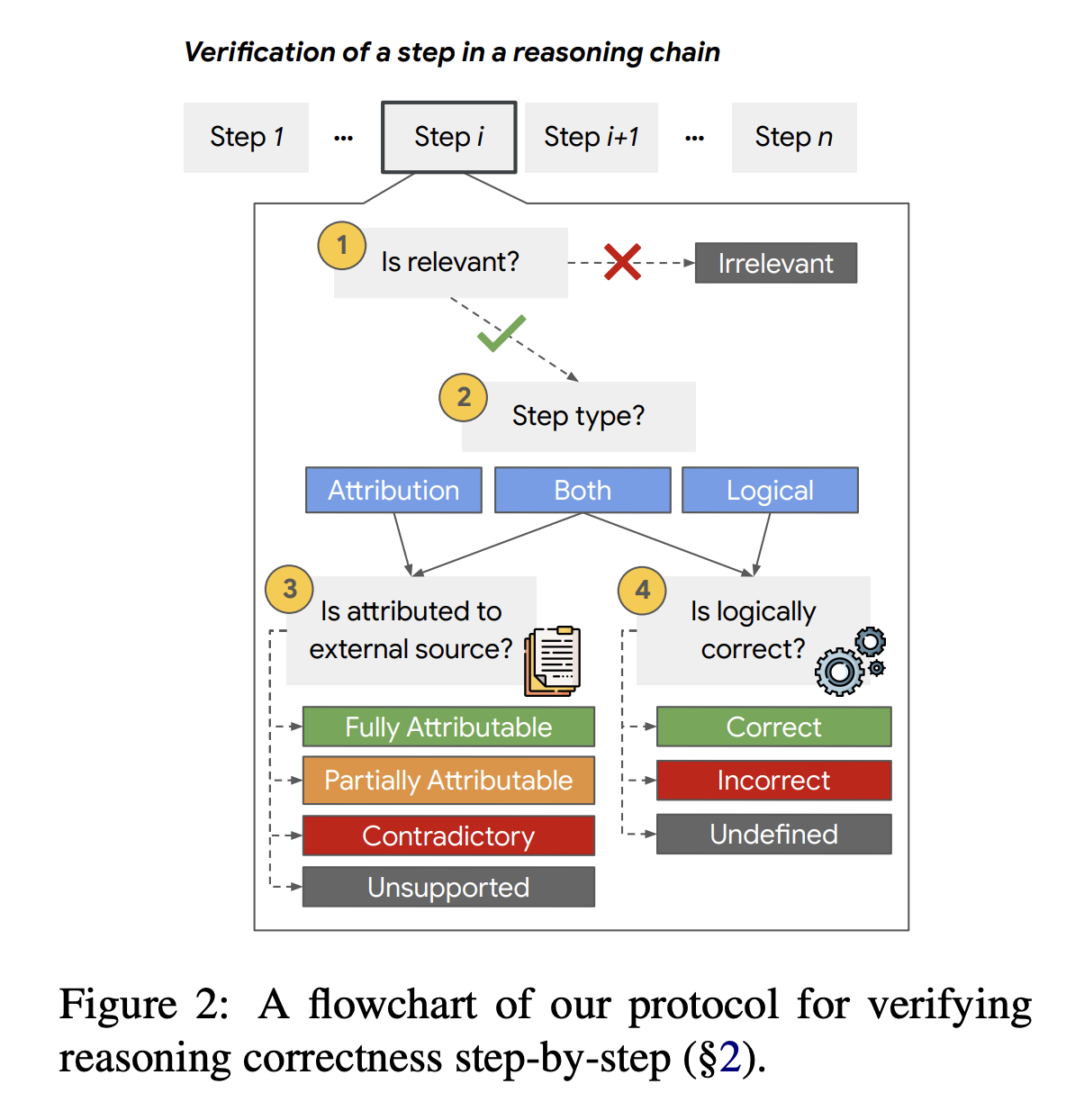
The prevailing approach for tackling complex reasoning tasks involves prompting language models to provide step-by-step answers, known as Chain-of-Thought (CoT) prompting. However, evaluating the correctness of reasoning steps is challenging due to the absence of high-quality, step-level annotated datasets. Recent efforts focus on automatic verification methods for reasoning chains, assessing informativeness and logical correctness. Despite the promise of these methods, evaluating them remains to be seen due to the difficulty and cost of collecting high-quality, step-level annotated data.
Researchers from Bar Ilan University, Google Research, Google DeepMind, and Tel Aviv University have developed REVEAL, a benchmark dataset for evaluating automatic verifiers of complex CoT reasoning in open-domain question answering. The dataset includes comprehensive labels for relevance, attribution to evidence passages, and logical correctness of each reasoning step in language models’ answers. The dataset allows versatile evaluation settings, and the research highlights challenges and opportunities for current verifiers, emphasizing the need for improvement in state-of-the-art solutions.

Prior work has explored using CoT prompting, initially as a technique to enhance the final answer’s performance in question answering. It has evolved into a focus on verifying the correctness of the CoT as an integral part of the answer. Various methods have been proposed for verifying reasoning chains, including those for LM evaluation, enhancement, and training. However, no existing work has presented a benchmark for reasoning chain correctness in information-seeking tasks. Recent studies have concentrated on verification methods and metrics.
The study mentions a new dataset called REVEAL, designed to benchmark automatic verifiers of complex CoT reasoning in open-domain question-answering settings. REVEAL includes comprehensive labels for the relevance, attribution to evidence passages, and logical correctness of each reasoning step in a language model’s answer. The researchers discuss the need for fine-grained step-level datasets to evaluate and improve the correctness of reasoning steps. The study also mentions using state-of-the-art language models to evaluate reasoning chains.

The REVEAL dataset was created to evaluate automatic verifiers of complex reasoning in open-domain question-answering settings. It provides comprehensive labels for relevance, attribution to evidence passages, and logical correctness of each reasoning step in a language model’s answer. REVEAL aims to address the need for fine-grained step-level datasets in this area and to improve the correctness of reasoning chains. It covers 704 questions from popular QA datasets and 1,002 CoT answers generated by three language models, evaluating the performance of state-of-the-art language models in this context. The contributions include a verification protocol, annotation schema, a new benchmark dataset, detailed analyses of challenges, and a study on current verifiers’ limitations.
In conclusion, the study mentions a methodology for human verification of reasoning chains, annotating the REVEAL dataset to benchmark automatic verifiers of LM reasoning in complex open-domain QA tasks. Findings indicate that LMs’ generated CoT often needs to be completed, with verifiers needing help, particularly in attribution and logical correctness. The REVEAL dataset offers comprehensive labels for each reasoning step, emphasizing the need for fine-grained datasets to enhance LM-generated reasoning. Overall, the research advances toward LMs capable of providing accurate and attributable reasoning, shedding light on challenges in verification, and suggesting avenues for improvement.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.