This AI Paper Unveils SecFormer: An Advanced Machine Learning Optimization Framework Balancing Privacy and Efficiency in Large Language Models
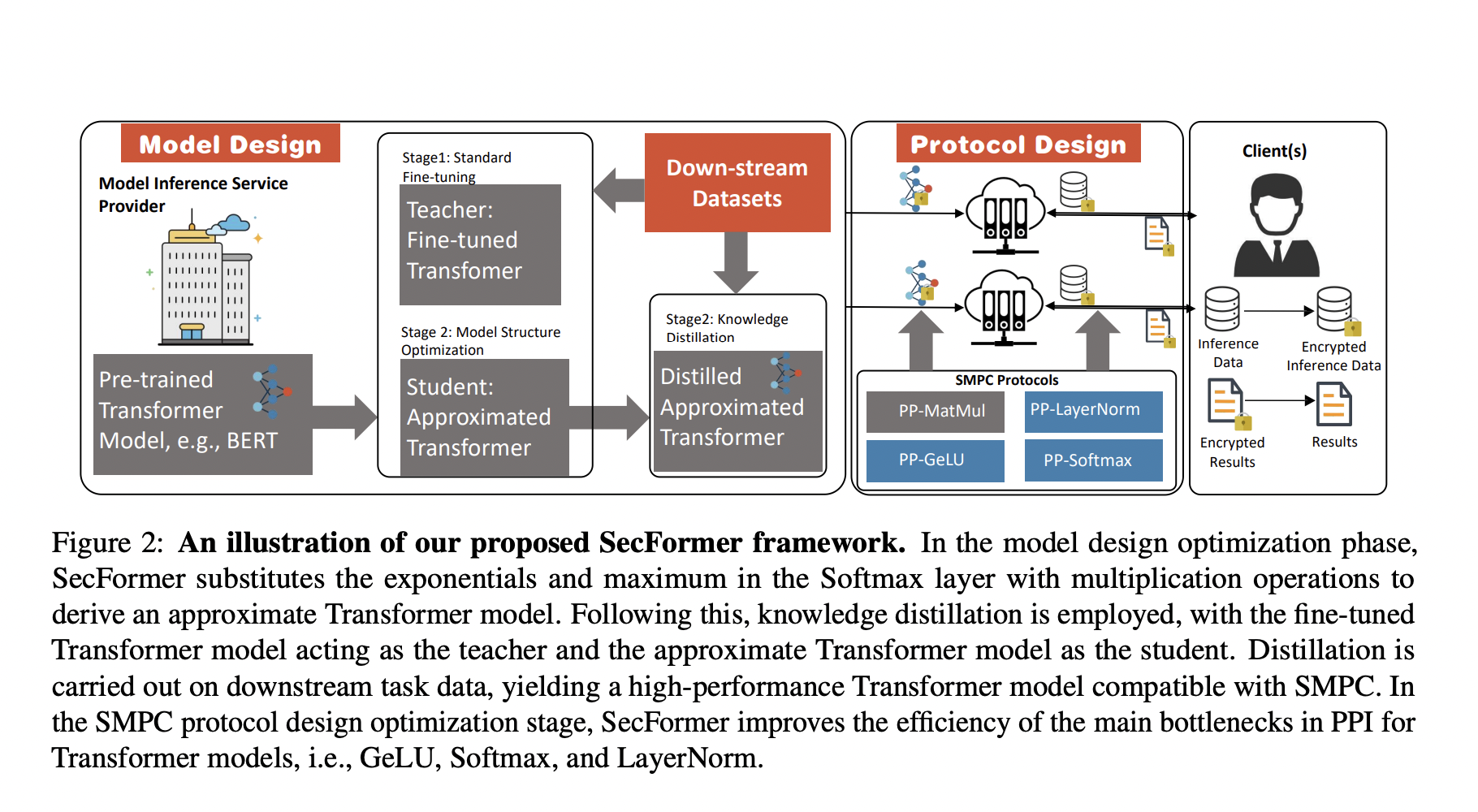
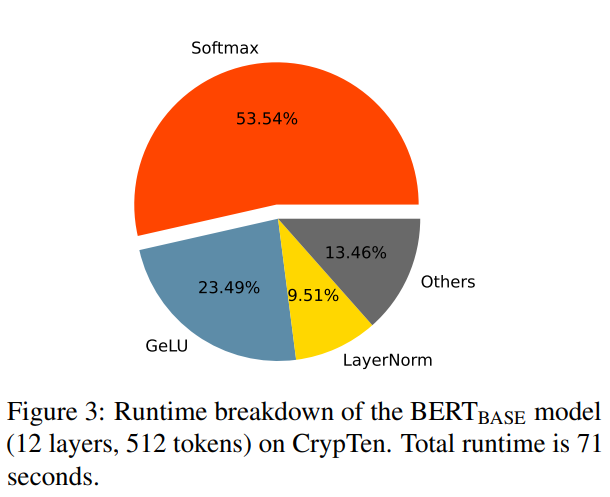
The increasing reliance on cloud-hosted large language models for inference services has raised privacy concerns, especially when handling sensitive data. Secure Multi-Party Computing (SMPC) has emerged as a solution for preserving the privacy of both inference data and model parameters. However, applying SMPC to Privacy-Preserving Inference (PPI) for large language models, particularly those based on the Transformer architecture, often results in significant performance issues. For instance, BERTBASE takes 71 seconds per sample via SMPC, compared to less than 1 second for plain-text inference (shown in Figure 3). This slowdown is attributed to the numerous nonlinear operations in the Transformer architecture, which need to be better suited for SMPC. To address this challenge, an advanced optimization framework named SecFormer (shown in Figure 2) is introduced to achieve an optimal balance between performance and efficiency in PPI for Transformer models.
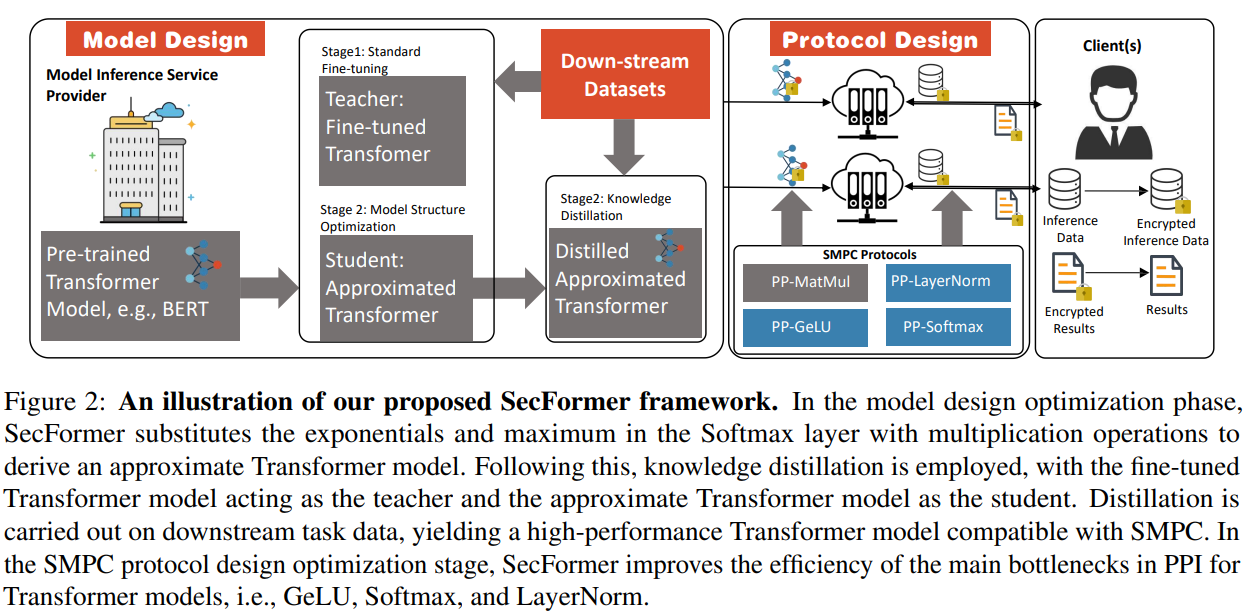
Large language models, such as those based on the Transformer architecture, have demonstrated exceptional performance across diverse tasks. However, the Model-as-a-Service (MaaS) paradigm poses privacy risks, as recent investigations indicate that a small number of samples can lead to the extraction of sensitive information from models like GPT-4. Accelerating PPI for Transformer models by replacing nonlinear operations with SMPC-friendly alternatives degrades performance. SecFormer takes a different approach, optimizing the balance between performance and efficiency through model design enhancements. It replaces high-overhead operations with innovative alternatives, such as substituting Softmax with a combination of multiplication and division operations. Knowledge distillation further refines the Transformer model, making it compatible with SMPC. SecFormer introduces a privacy-preserving GeLU algorithm based on segmented polynomials and efficient privacy-preserving algorithms for LayerNorm and Softmax, ensuring privacy while maintaining performance.
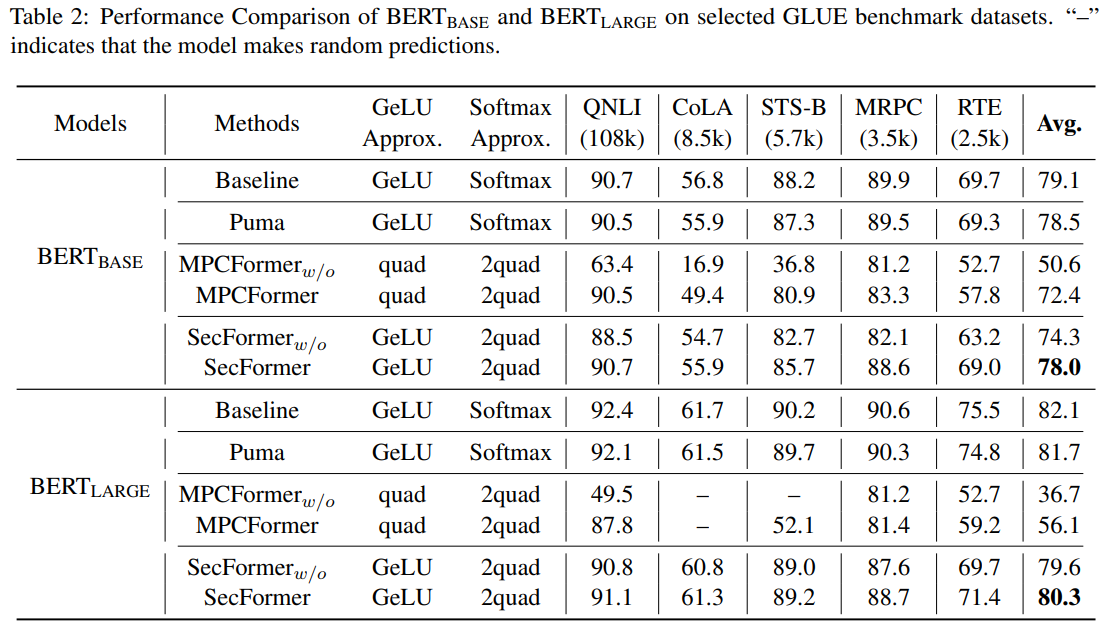
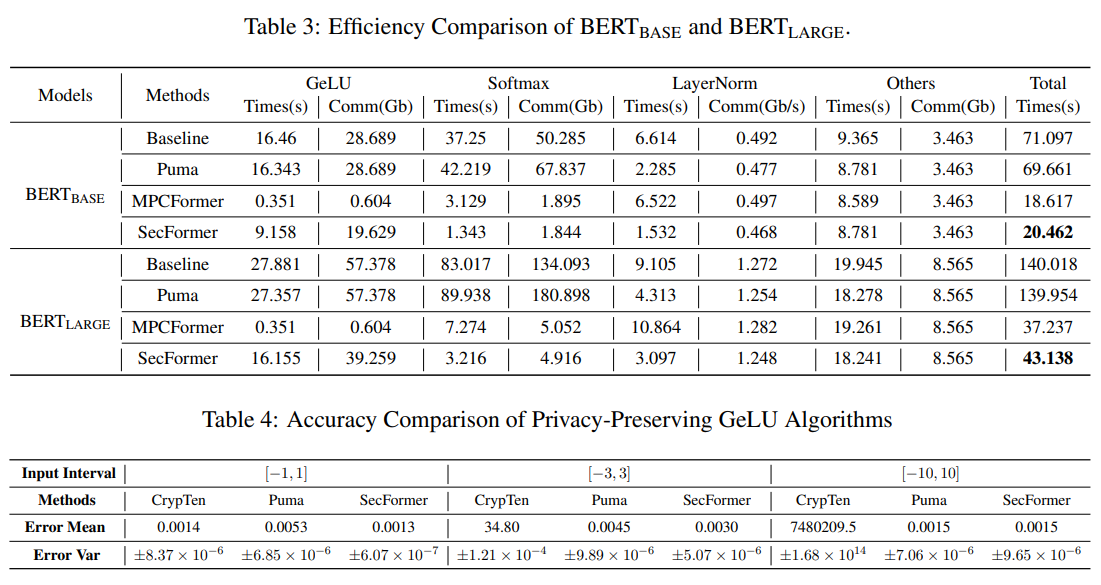
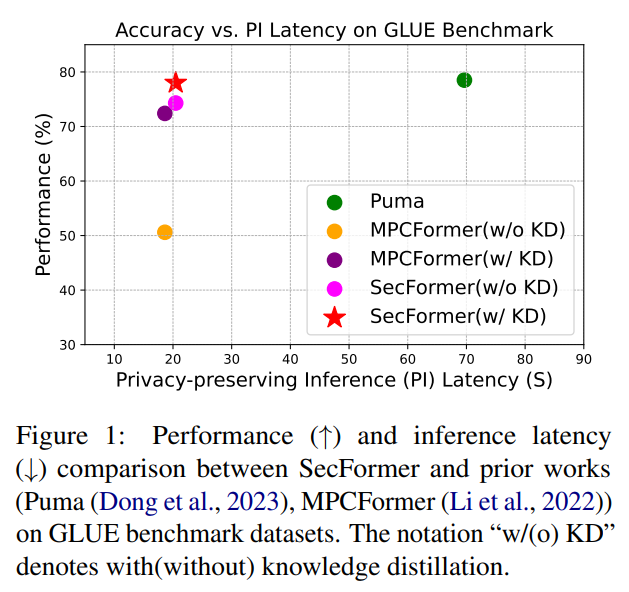
Evaluation of the GLUE (shown in Figure 1 and Table 2) benchmark dataset using Transformer models like BERTBASE and BERTLARGE demonstrates that SecFormer outperforms state-of-the-art approaches in terms of performance and efficiency. With an average improvement of 5.6% and 24.2%, SecFormer balances performance and efficiency in PPI. Comparisons with existing frameworks based on model design and SMPC protocol optimizations reveal that SecFormer achieves a speedup of 3.4 and 3.2 times in PPI while maintaining comparable performance levels. The framework’s effectiveness is showcased through a series of experiments (shown in Table 3), validating its potential to enhance large language models and ensure stringent privacy (shown in Table 4) standards in complex linguistic landscapes. In summary, SecFormer presents a scalable and effective solution, promising high performance while prioritizing privacy and efficiency in large language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.