This AI Paper Unveils the Future of MultiModal Large Language Models (MM-LLMs) – Understanding Their Evolution, Capabilities, and Impact on AI Research
Recent developments in Multi-Modal (MM) pre-training have helped enhance the capacity of Machine Learning (ML) models to handle and comprehend a variety of data types, including text, pictures, audio, and video. The integration of Large Language Models (LLMs) with multimodal data processing has led to the creation of sophisticated MM-LLMs (MultiModal Large Language Models).
In MM-LLMs, pre-trained unimodal models, particularly LLMs, are mixed with additional modalities to capitalize on their strengths. Compared to training multimodal models from scratch, this method lowers computing costs while enhancing the model’s capacity to handle various data types.
Models such as GPT-4(Vision) and Gemini, which have demonstrated remarkable capabilities in comprehending and producing multimodal content, are examples of recent breakthroughs in this field. Multimodal understanding and generation have been the subject of research, with examples of models such as Flamingo, BLIP-2, and Kosmos-1, which are capable of processing images, sounds, and even video in addition to text.
Integrating the LLM with other modal models in a way that allows them to cooperate well is one of the main problems with MM-LLMs. For the various modalities to function in accordance with human intents and comprehension, they must be aligned and tuned. Researchers have been focussing on increasing the capabilities of conventional LLMs while maintaining their innate capacity for reasoning and decision-making and allowing them to perform well across a wider range of multimodal tasks.
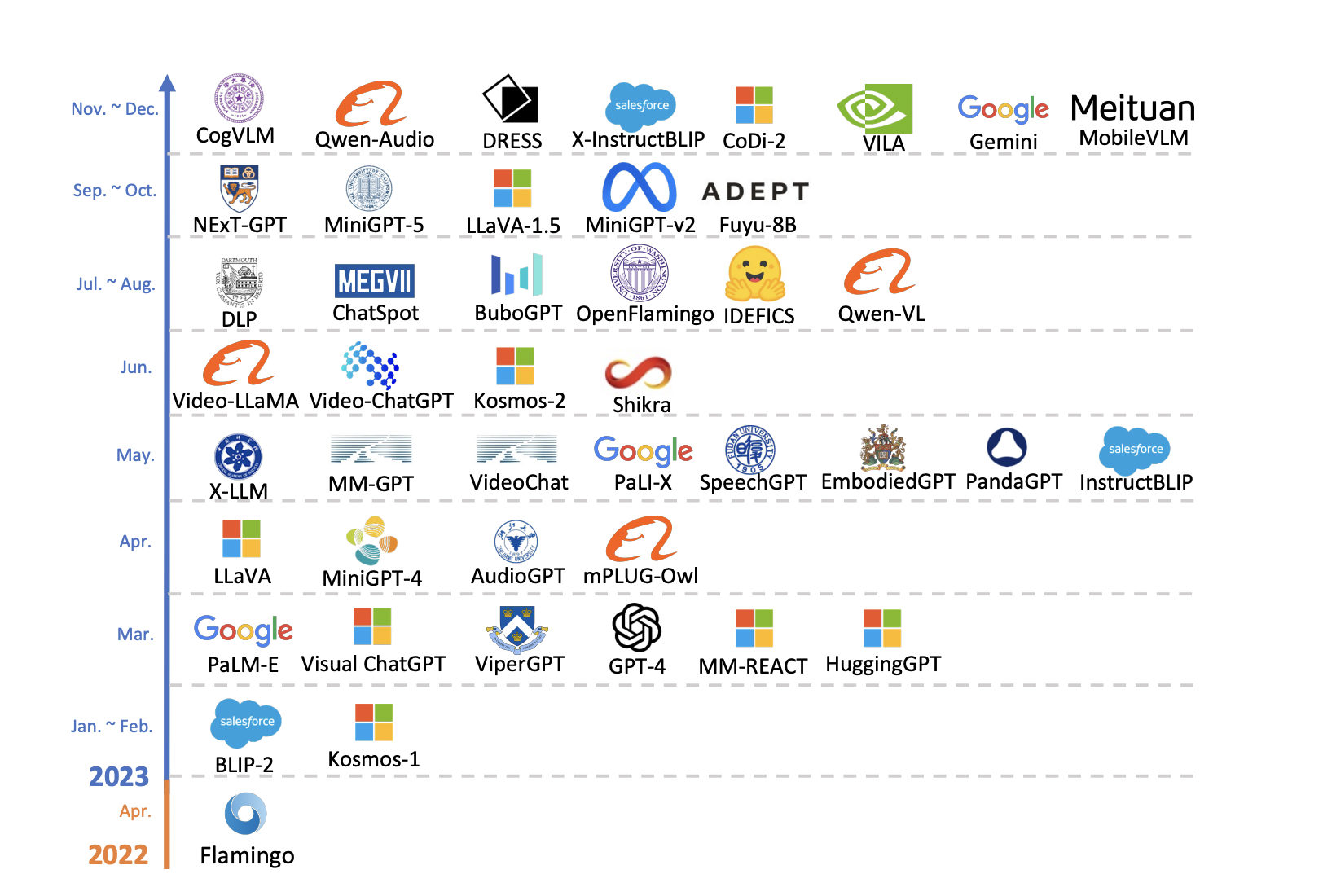
In recent research, a team of researchers from Tencent AI Lab, Kyoto University, and Shenyang Institute of Automation conducted an extensive study about the field of MM-LLMs. Starting with the definition of general design formulations for model architecture and the training pipeline, the study covers a number of topics. The team in their study has offered a basic comprehension of the essential ideas behind the creation of MM-LLMs.
After providing an outline of design formulations, the current state of MM-LLMs has been explored. For each of the 26 identified MM-LLMs, a brief introduction has been given, emphasizing their unique compositions and unique qualities. The team has shared that the study provides its readers with an understanding of the variety and subtleties of models that are currently in use within the MM-LLMs area.
The MM-LLMs have been evaluated using industry standards. The assessment has thoroughly explained these models’ performance against industry standards and in real-world circumstances. The study has also summarized important training approaches or formulas that have been successful in raising the overall effectiveness of MM-LLMs.

The five key components of the general model architecture of MultiModal Large Language Models (MM-LLMs) have been examined, which are as follows.
- Modality Encoder: This part translates input data, such as text, images, audio, and so on, from several modalities into a format that the LLM can comprehend.
- LLM Backbone: The fundamental abilities of language processing and generation are provided by this component, which is frequently a pre-trained model.
- Modality Generator: It is crucial for models that concentrate on multimodal comprehension and generation. It converts the LLM’s outputs into several modalities.
- Input projector – It is a crucial element in the process of integrating and aligning the encoded multimodal inputs with the LLM. With an input projector, the input is successfully transmitted to the LLM backbone.
- Output Projector: It converts the LLM’s output into a format appropriate for multimodal expression once the LLM has processed the data.
In conclusion, this research provides a thorough summary of MM-LLMs as well as insights into the effectiveness of present models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.