This AI Research Analyzes The Zero-Shot Learning Ability of ChatGPT by Evaluating It on 20 Popular NLP Datasets
By conditioning the model on suitable prompts, large language models (LLMs) have been proven to do a number of NLP tasks with zero-shot learning. In simpler words, LLMs do not rely on training data for a given downstream job. Current LLMs are still prone to different errors in zero-shot learning.
The NLP community has been paying much attention to the ChatGPT LLM that OpenAI released not long ago. ChatGPT was developed using reinforcement learning to train a GPT-3.5 series model based on user input (RLHF). The core of RLHF is the three-stage process of supervised language model training, human preference comparison data collection and reward model training, and reinforcement learning-based language model optimization.
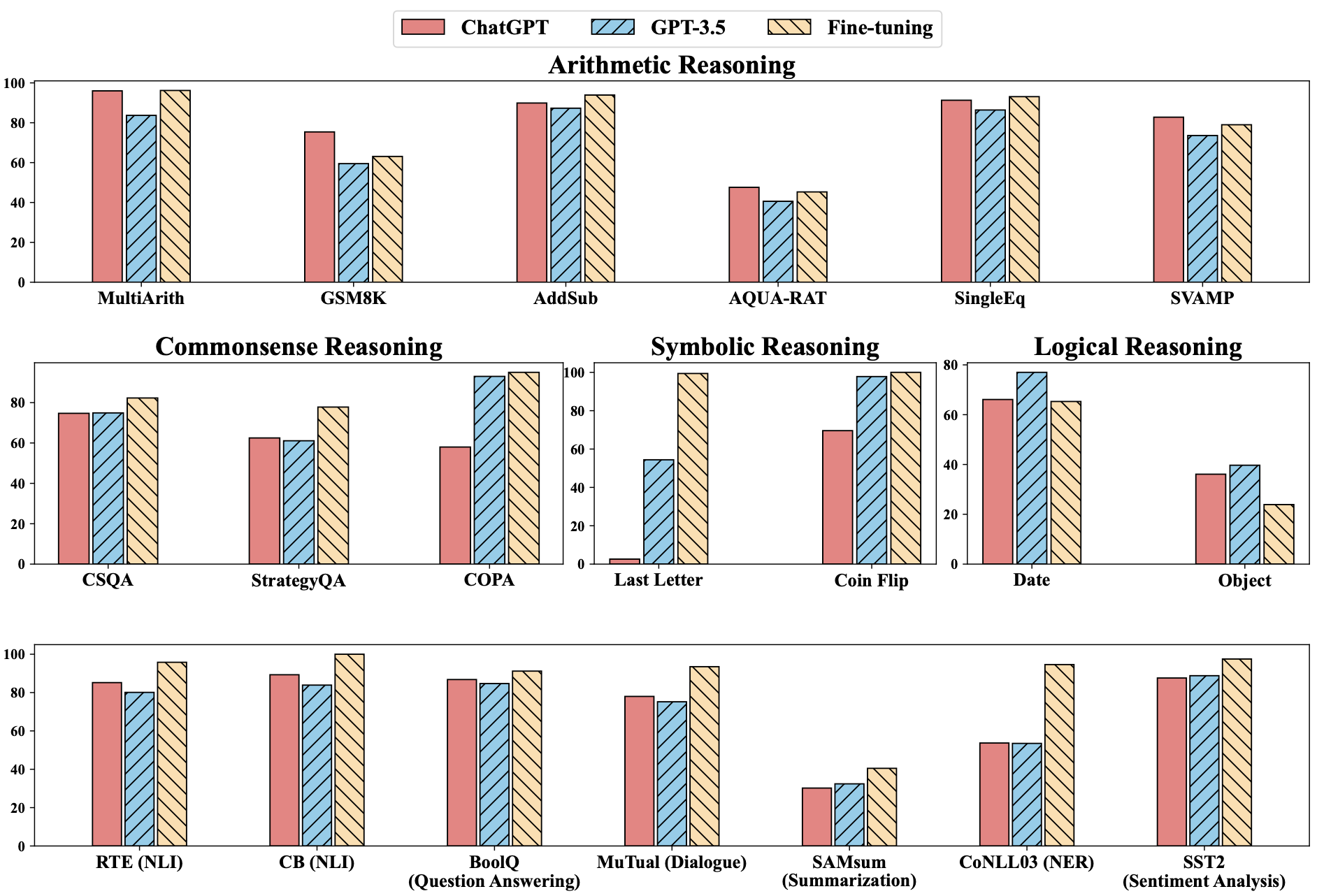
Although ChatGPT demonstrates considerable competence as a generalist model that can handle several tasks, it frequently underperforms models focused on a single job. In arithmetic reasoning challenges, ChatGPT’s higher reasoning capacity is empirically supported. However, ChatGPT frequently performs worse than GPT-3.5 in tasks that require symbolic, logical, and commonsense reasoning, such as by producing ambiguous answers.
To close this gap in the literature, a new study by Nanyang Technological University, Shanghai Jiao Tong University, Georgia Institute of Technology, and Stanford University conducted a comprehensive investigation into ChatGPT’s zero-shot learning capability. For this, the researchers tested it on a wide range of NLP datasets covering 7 illustrative task categories, including reasoning, natural language inference, question answering (reading comprehension), dialogue, summarization, named entity recognition, and sentiment analysis.
The study focuses on finding ChatGPT capabilities for solving various NLP problems. The researchers empirically compare the capabilities of ChatGPT with the state-of-the-art GPT-3.5 model to provide answers to these queries.
ChatGPT beats GPT-3.5 on reasoning-heavy tasks like finding logical links between text pairs and natural language inference tasks like question responding (reading comprehension). The findings also show that ChatGPT excels at coping with material consistent with reality (i.e., better at classifying entailment rather than non-entailment). ChatGPT creates more lengthy summaries and is less effective than GPT-3.5 when used for summarization. Unfortunately, the summarization quality is harmed by the zero-shot instruction’s explicit length limitation, resulting in even lower performance.
The team hopes their work inspires other researchers to explore ways to put ChatGPT’s reasoning and dialogue capabilities to use in NLP applications and overcome the limits of generalist models in areas where they’ve historically struggled.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.