This AI Research Dives Into The Limitations and Capabilities of Transformer Large Language Models (LLMs), Empirically and Theoretically, on Compositional Tasks
ChatGPT is trending, and millions of people are using it every day. With its incredible capabilities of imitating humans, such as question answering, generating unique and creative content, summarizing massive textual data, code completion, and developing highly useful virtual assistants, ChatGPT is making our lives easier. Developed by OpenAI, ChatGPT is based on GPT 3.5 (Generative Pre-Trained Transformer) and GPT 4’s transformer architecture. GPT 4, the latest version of language models released by OpenAI, is multimodal in nature, i.e., it takes in input in the form of text and images, unlike the previous versions. Even other Large Language Models (LLMs) like PaLM, LLaMA, and BERT are being used in applications of various domains involving healthcare, E-commerce, finance, education, etc.
A team of researchers has highlighted the difference between the impressive performance of LLMs like GPT on complex tasks and their struggles with simple tasks in a recently released research paper. Diving into the limitations and capabilities of Transformer LLMs, the team has conducted experiments on three representative compositional tasks: multi-digit multiplication, logic grid puzzles, and a classic dynamic programming problem. These tasks involve breaking down problems into smaller steps and combining those steps to produce an exact solution.
With the aim of studying the limits of Transformers in solving compositional tasks that require multi-step reasoning, the authors have proposed two hypotheses. The first is that the Transformers accomplish tasks by linearizing multi-step reasoning into path matching, thus relying on pattern-matching and shortcut learning rather than actually comprehending and implementing the underlying computational rules required to develop proper solutions. This approach enables fast and accurate predictions in similar patterns during training but fails to generalize to uncommon complex examples. The second hypothesis states that Transformers may have inherent limitations while trying to solve high-complexity compositional tasks having unique patterns. Early computational errors might spread and result in severe compounding errors in later steps, preventing the models from arriving at the right solution.
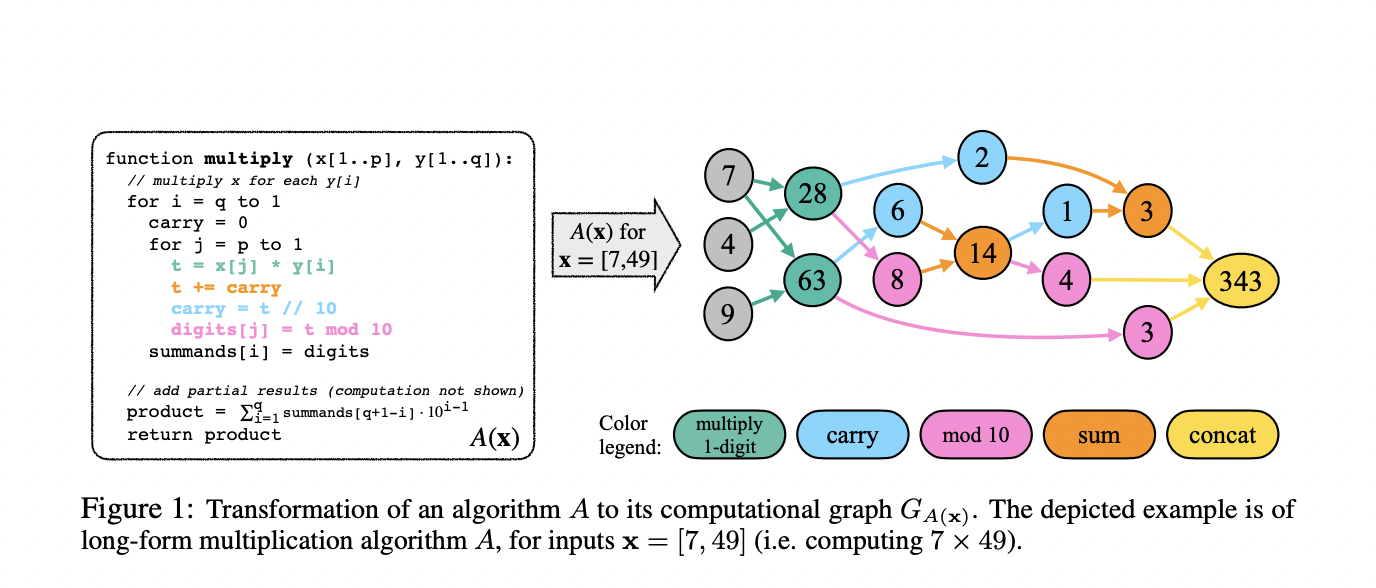
The authors have formulated the compositional tasks as computation graphs in order to investigate the two hypotheses. These graphs decompose the process of solving problems into smaller, more manageable submodular functional steps, enabling structured measures of problem complexity and verbalization of computing steps as input sequences to language models. They even use information gain to make predictions about the patterns that models would probably learn based on the underlying task distribution without running full computations within the graph.
Based on the empirical findings, the authors have proposed that the Transformers handle compositional challenges by reducing multi-step reasoning into linearized subgraph matching. They have provided theoretical arguments based on abstract multi-step reasoning problems, which highlight that as the task complexity increases, Transformers’ performance rapidly deteriorates. This shows that the models might already be constrained in their ability to handle compositional problems of great complexity.
In conclusion, the empirical and theoretical results imply that rather than a thorough comprehension of the underlying thinking processes, Transformers’ performance is mostly driven by pattern matching and subgraph matching, which also supports the idea that Transformers would find it difficult to do increasingly difficult tasks.
Check Out The Paper. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.