This AI Research Evaluates the Correctness and Faithfulness of Instruction-Following Models For Their Ability To Perform Question-Answering
Recently introduced Large Language Models (LLMs) have taken the Artificial Intelligence (AI) community by storm. These models have been able to successfully imitate human beings by using super-good Natural Language Processing (NLP), Natural Language Generation (NLG) and Natural Language Understanding (NLU). LLMs have become famous for imitating humans for having realistic conversations and are capable of answering simple and complex questions, content generation, code completion, machine translation, and text summarization. The goal of NLP is to make it possible for computer systems to comprehend and react to commands given in natural language, enabling people to engage with them in a more natural and flexible way, the best example of which is the instruction following models.
These models are trained using LLMs, supervised examples, or other types of supervision, and exposure to thousands of tasks written as natural language instructions. In recent research, a team from Mila Quebec AI Institute, McGill University, and Facebook CIFAR AI Chair has researched evaluating the performance of instruction-following models for their ability to perform question-answering (QA) on a given set of text passages. These models can answer questions when provided with a prompt describing the task, the question, and relevant text passages retrieved by a retriever, and the responses produced by these models are known to be natural and informative, which helps build users’ trust and engagement.
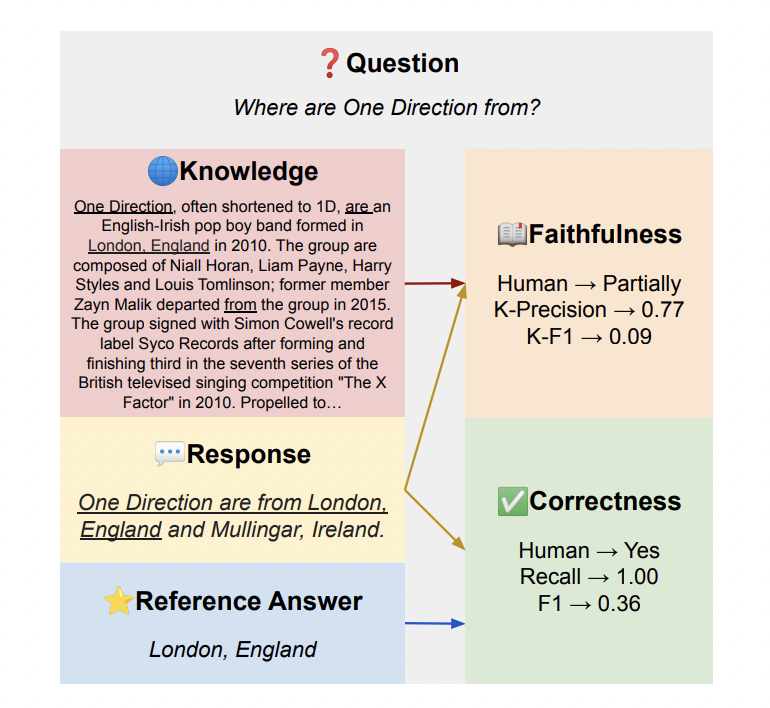
These models can respond to user queries naturally and fluently by only adding retrieved documents and instructions to their input. However, this extra verbosity makes it difficult for conventional QA evaluation metrics like exact match (EM) and F1 score to effectively quantify model performance. This is due to the possibility that the model’s response may include more details that the reference answer omits while still being accurate. The team has provided two criteria for measuring instruction-following models in retrieval-augmented quality assurance (QA) in order to overcome this problem.
- Regarding information necessity, accuracy: This dimension evaluates how well the model satisfies the informational requirements of a user. It is concerned with whether the generated response includes pertinent information, even if it goes beyond what is mentioned directly in the reference answer.
- Fidelity in relation to information provided: This dimension assesses how well the model grounds answers in the knowledge presented. A true model should refrain from responding when irrelevant information is presented, in addition to giving precise answers when it is accessible.
The authors have evaluated several recent instruction-following models on three diverse QA datasets: Natural Questions for open-domain QA, HotpotQA for multi-hop QA, and TopiOCQA for conversational QA. They analyzed 900 model responses manually and compared the results with different automatic metrics for accuracy and faithfulness. Their research has suggested that recall, which measures the percentage of tokens from the reference answer that are also present in the model response, correlates more strongly with correctness than lexical overlap metrics like EM or F1 score. Compared to other token-overlap metrics for faithfulness, K-Precision, which is the percentage of model answer tokens that exist in the knowledge snippet, has a stronger correlation with human judgments.
In conclusion, this study seeks to advance a more thorough assessment of instruction-following models for QA tasks, taking into account both their advantages and disadvantages. The team has promoted additional advancement in this area by making their code and data accessible on their GitHub repository
Check out the Paper, GitHub, and Tweet. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.