This AI Research Explains the Synthetic Personality Traits in Large Language Models (LLMs)
An individual’s personality consists of a unique combination of qualities, characteristics, and ways of thinking. It shapes our most fundamental social interactions and preferences due to our shared biological and environmental histories. Due to their extensive exposure to human-generated data during training, LLMs can convincingly portray human-like personas in their outputs and, in effect, demonstrate a synthetic personality.
Due to their extensive exposure to human-generated data during training, LLMs can convincingly portray human-like personas in their outputs and, in effect, demonstrate a synthetic personality. Recent research has attempted to identify unintended consequences of LLMs’ enhanced abilities, such as the tendency to produce violent language and the production of deceptive and manipulative language in experiments. Conversations, explanations, and knowledge extraction from LLMs are not always reliable.
Understanding the personality trait-related properties of the language created by these models is vital as LLMs become the dominant human-computer interaction (HCI) interface, as is learning how to safely, appropriately, and effectively engineer personality profiles generated by LLMs. Researchers have studied methods including few-shot prompting to lessen the impact of negative and severe personality traits in LLM results. Even though LLMs have very variable outputs and are hypersensitive to prompting, no work has yet addressed how to scientifically and systematically quantify their personality.
Researchers from Google DeepMind, the University of Cambridge, Google Research, Keio University, and the University of California, Berkeley propose rigorous, verified psychometric approaches to characterize and mold LLM-based personality syntheses.
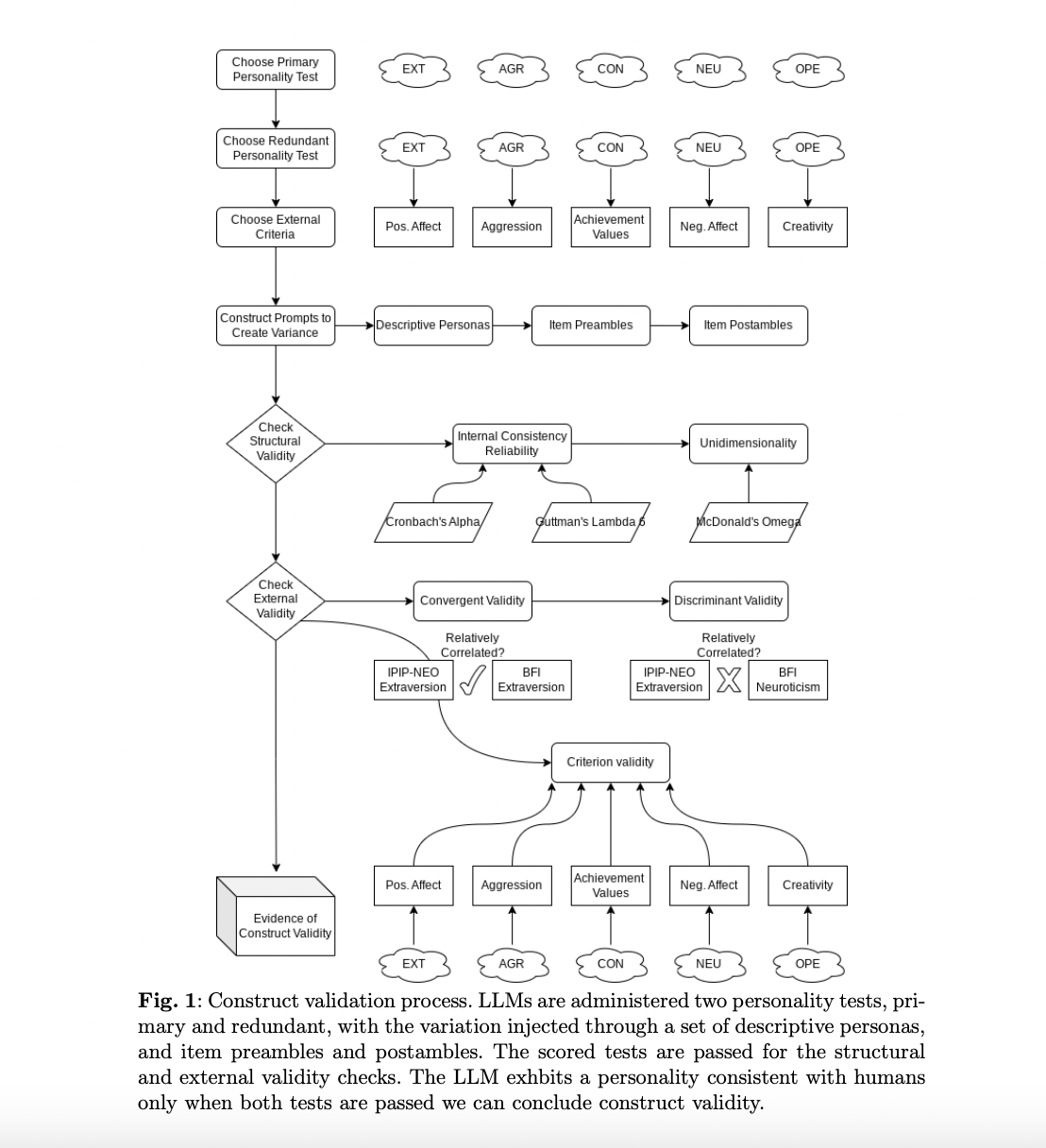
The team first creates a methodology for utilizing previously existing psychometric tests to establish the construct validity of characterizing personalities in LLM-generated literature. They present a novel approach of mimicking population variance in LLM responses through controlled prompting to test the statistical correlations between personality and its external correlates as they exist in human social science data. Finally, they contribute a method for molding personality that operates independently of LLM and results in observable changes in trait levels.
The researchers test the approach on LLMs ranging in size and training methods in two natural interaction settings: MCQA and long-form text generation. The findings show the following observations:
- LLMs can reliably and validly simulate personality in their outputs (under certain prompting configurations.
- Evidence of LLM-simulated personality’s reliability and validity is stronger for larger, instruction-fine-tuned models.
- Personality in LLM outputs can be shaped along desired dimensions to mimic specific personality profiles.
Check out the Paper. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.