This AI Research from Apple Unveils a Breakthrough in Running Large Language Models on Devices with Limited Memory
Researchers from Apple have developed an innovative method to run large language models (LLMs) efficiently on devices with limited DRAM capacity, addressing the challenges posed by intensive computational and memory requirements. The paper introduces a strategy that involves storing LLM parameters on flash memory and dynamically bringing them to DRAM as needed during inference. It focuses on optimizing two critical areas:
- minimizing the volume of data transferred from flash
- reading data in larger, more contiguous chunks.
To achieve this, the team constructs an inference cost model that aligns with flash memory behavior, leading to the development of two principal techniques: “windowing” and “row-column bundling.”
The “windowing” technique strategically reduces data transfer by reusing previously activated neurons. By maintaining a sliding window of recent input tokens in memory and selectively loading neuron data that differs from its predecessors, the researchers achieve efficient memory utilization, minimizing the amount of data loaded from the flash memory for each inference query. While the “row-column bundling” technique leverages flash memory’s sequential data access strengths. By storing concatenated rows and columns of up-projection and down-projection layers together in flash memory, the team increases the size of data chunks read, optimizing flash-memory throughput.
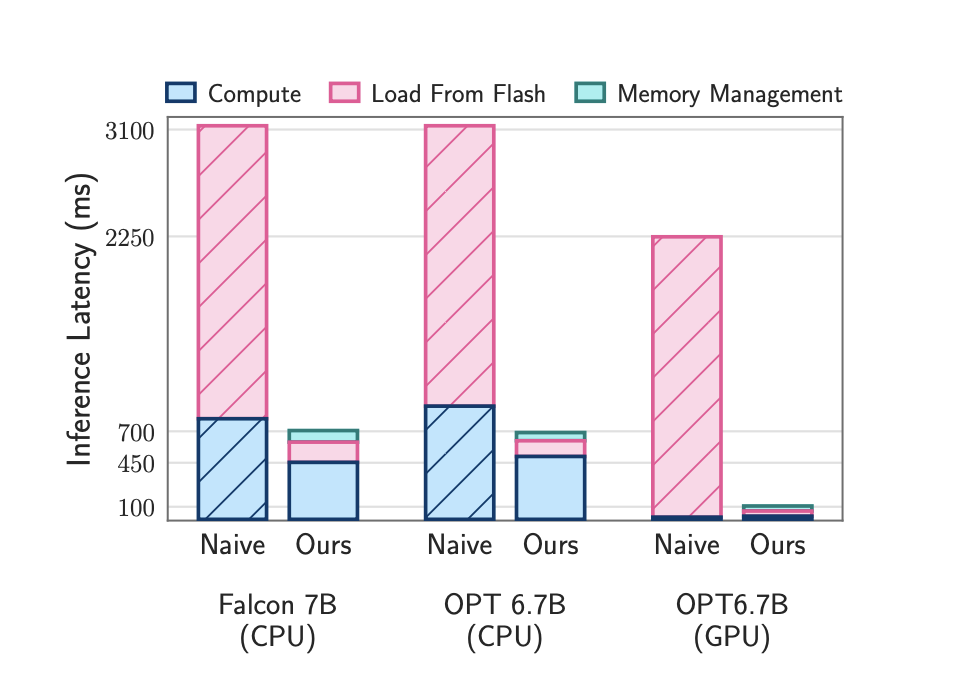
The researchers have exploited the sparsity observed in FeedForward Network (FFN) layers of LLMs, allowing for the selective loading of non-zero parameters from flash memory. A hardware-inspired cost model, incorporating flash memory, DRAM, and computing cores, guides the optimization process. The outcomes of the study demonstrate the effectiveness of the proposed method. LLMs up to twice the size of available DRAM can be run, achieving a remarkable 4-5x and 20-25x increase in inference speed compared to naive loading approaches on CPU and GPU, respectively. The results show the method leads to very small I/O latency for the OPT 6.7B Model and 9-10 times faster baseline latency.
The approach integrates sparsity awareness, context-adaptive loading, and a hardware-oriented design, paving the way for more efficient LLM inference on devices with limited memory. The methodology proves crucial for overcoming the challenge of loading and running large models on resource-constrained devices, where the standard approach of loading the entire model into DRAM for inference could be more practical due to memory limitations.
In conclusion, this strategy, grounded in a deep understanding of flash memory and DRAM characteristics, offers a promising solution to the computational bottleneck associated with running LLMs on devices with constrained memory. The study addresses current challenges and sets a precedent for future research, emphasizing the significance of considering hardware characteristics in the development of inference-optimized algorithms for advanced language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.
Credit: Source link
Comments are closed.