This AI Research from China Introduces 4K4D: A 4D Point Cloud Representation that Supports Hardware Rasterization and Enables Unprecedented Rendering Speed
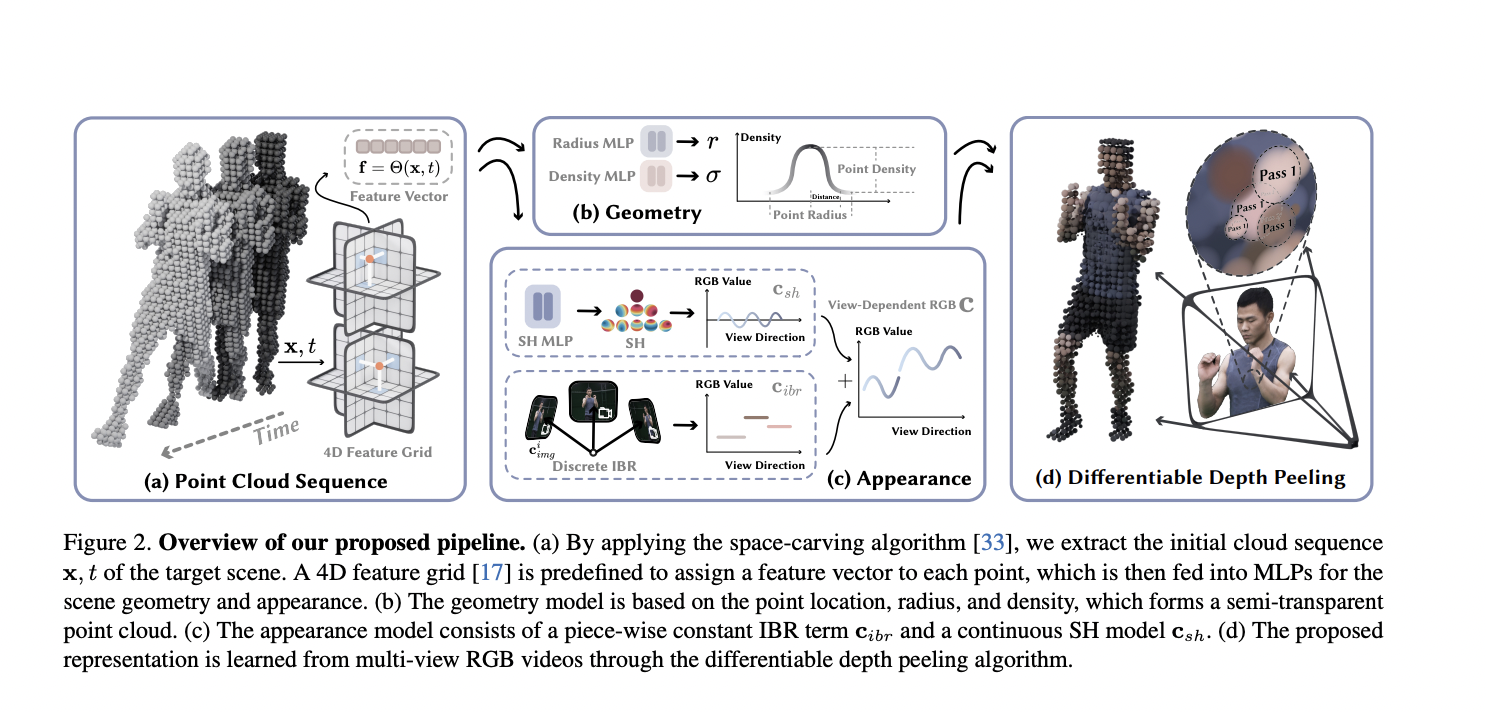
Dynamic view synthesis is a computer vision and graphic task attempting to reconstruct dynamic 3D scenes from captured videos and generate immersive virtual playback. This technique’s practicality relies on its high-fidelity real-time rendering capability, enabling its use in VR/AR, sports broadcasting, and artistic performance capture. Conventional approaches represent dynamic 3D scenes as textured mesh sequences and reconstruct them using complex hardware, limiting their applicability to controlled environments. Implicit neural representations have recently demonstrated significant success in reconstructing dynamic 3D scenes from RGB videos through differentiable rendering. Recently developed techniques model the target scene as a dynamic radiance field and employ volume rendering to synthesize images, comparing them with input images for optimization. Despite achieving impressive results in dynamic view synthesis, existing approaches typically demand seconds or even minutes to render an image at 1080p resolution due to the resource-intensive network evaluation.
Motivated by static view synthesis methodologies, specific dynamic view synthesis techniques enhance rendering speed by reducing either the cost or the number of network evaluations. Employing these strategies, representations known as MLP Maps achieve a rendering speed of 41.7 fps for dynamic foreground humans. However, the challenge of rendering speed persists, as MLP Maps achieves real-time performance only when synthesizing moderate-resolution images (384×512). When rendering 4K resolution images, its speed drops to 1.3 FPS.
The present study introduces a novel neural representation, termed 4K4D, designed for modeling and rendering dynamic 3D scenes. 4K4D demonstrates significant improvements over previous dynamic view synthesis approaches in rendering speed while maintaining competitiveness in rendering quality. The overview of the system is illustrated below.
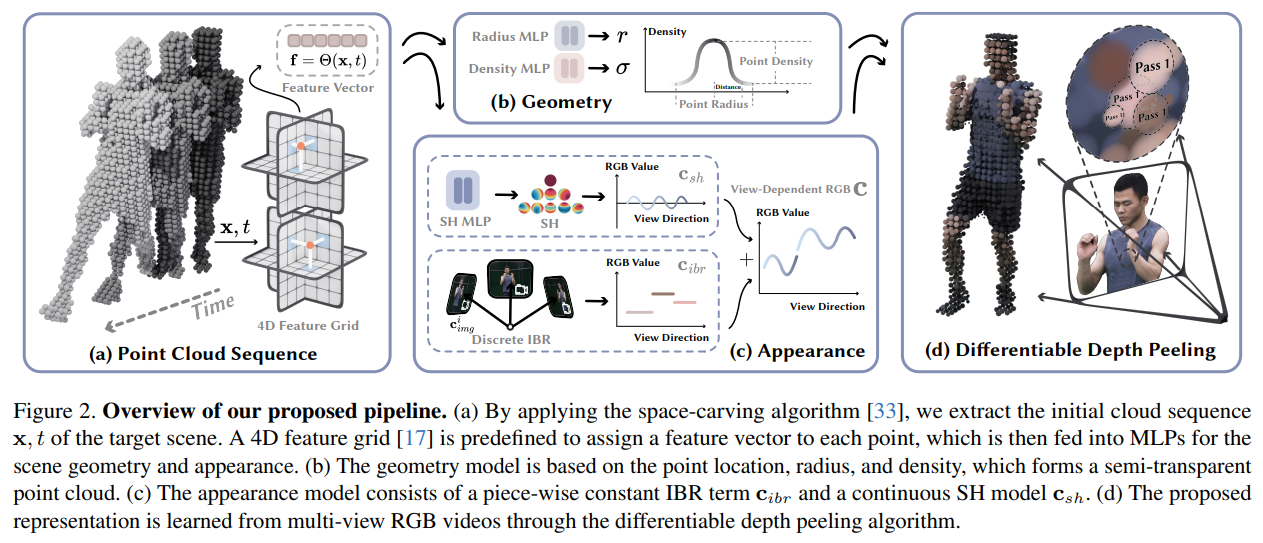
The core innovation lies in a 4D point cloud representation and a hybrid appearance model. Specifically, for the dynamic scene, a coarse point cloud sequence is obtained using a space carving algorithm, with the position of each point modeled as a learnable vector. A 4D feature grid is introduced to assign a feature vector to each point, which is then input into MLP networks to predict the point’s radius, density, and spherical harmonics (SH) coefficients. The 4D feature grid naturally applies spatial regularization to the point clouds, enhancing optimization robustness. Furthermore, a differentiable depth peeling algorithm is developed, utilizing the hardware rasterizer to achieve unprecedented rendering speed.
The study identifies challenges in the MLP-based SH model’s representation of dynamic scene appearance. To address this, an image blending model is introduced to complement the SH model in representing the scene’s appearance. An important design choice ensures the independence of the image blending network from the viewing direction, enabling pre-computation after training to enhance rendering speed. However, this strategy introduces a challenge in discrete behavior along the viewing direction, which is mitigated using the continuous SH model. Unlike 3D Gaussian Splatting, which exclusively employs the SH model, this hybrid appearance model fully capitalizes on information captured by input images, effectively enhancing rendering quality.
Extensive experiments reported by the authors claim that 4K4D achieves orders of magnitude faster rendering while notably outperforming state-of-the-art methods in terms of rendering quality. According to the numbers, utilizing an RTX 4090 GPU, this method achieves up to 400 FPS at 1080p resolution and 80 FPS at 4K resolution.
A visual comparison with state-of-the-art techniques is reported below.

This was the summary of 4K4D, a novel AI 4D point cloud representation that supports hardware rasterization and enables unprecedented rendering speed. If you are interested and want to learn more about it, please feel free to refer to the links cited below.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.