This AI Research Introduces Atom: A Low-Bit Quantization Technique for Efficient and Accurate Large Language Model (LLM) Serving
Large Language Models are the most recent introduction in the Artificial Intelligence community, which has taken the world by storm. These models, due to their incredible capabilities, are being used by everyone, be it researchers, scientists or even students. With their human-imitating potential to answer questions, generate content, summarise text, complete codes and so on, these models have come a long way.
LLMs are needed in a number of domains, including sentiment analysis, intelligent chatbots, and content creation. These models utilise a lot of computational power, because of which GPU resources are effectively used to increase throughput. This is done by batching several user requests, and to further improve memory efficiency and computing capacity, LLM quantisation techniques are used. However, existing quantisation approaches, like 8-bit weight-activation quantisation, don’t really take advantage of what newer GPUs can accomplish. Since the integer operators on these GPUs are 4-bit, the current quantisation techniques are not designed for maximum efficiency.
To address this issue, a team of researchers has introduced Atom, a new method that maximises the serving throughput of LLMs. Atom is a low-bit quantisation technique created to increase throughput significantly without sacrificing precision. It uses low-bit operators and low-bit quantisation to reduce memory usage in order to achieve this. It uses a special combination of fine-grained and mixed-precision quantisation to retain excellent accuracy.
The team has shared that Atom has been evaluated in terms of 4-bit weight-activation quantisation configurations when serving. The results demonstrated that Atom can maintain latency within the same goal range while improving end-to-end throughput by up to 7.73 times when compared to the typical 16-bit floating-point (FP16) approach and 2.53 times when compared to 8-bit integer (INT8) quantisation. This makes Atom a viable solution for catering to the increasing demand for their services because it maintains the desired level of response time and greatly increases the speed at which LLMs can process requests.
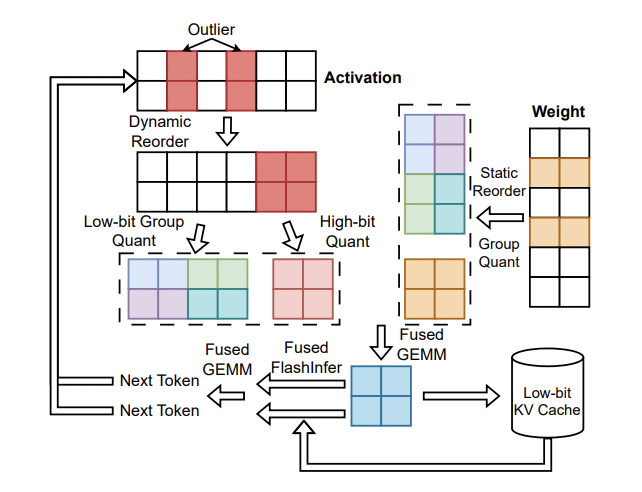
The researchers have summarised the primary contributions as follows.
- LLM serving has been thoroughly analysed as the first step in the study’s performance analysis. The important performance benefits that come from using low-bit weight-activation quantisation approaches have been identified.
- A unique and precise low-bit weight-activation quantisation technique called Atom has been presented.
- The team has shared that Atom employs a variety of strategies to guarantee peak performance. It uses mixed precision, which uses reduced precision for the remaining key activations and weights while maintaining accuracy for the former. Fine-grained group quantisation has been used to reduce mistakes during the quantisation process.
- Atom employs dynamic activation quantisation, which reduces quantisation mistakes by adjusting to the unique distribution of each input. To further improve overall performance, the method additionally takes care of the KV-cache’s quantisation.
- The research has also proposed an integrated framework for long-term management (LLM) servicing. The team has codesigned an effective inference system, constructing low-bit GPU kernels and showing off Atom’s useful end-to-end throughput and latency in an actual setting.
- Atom’s performance has been thoroughly assessed, which shows that Atom greatly increases LLM serving throughput, with throughput gains of up to 7.7x possible at the expense of a minuscule loss of accuracy.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.