This AI Research Introduces BOFT: A New General Finetuning AI Method for the Adaptation of Foundation Models
The recent developments in the field of Artificial Intelligence, especially the introduction of Large Language Models, have paved the way for AI in almost every domain. Foundation models, such as ChatGPT and Stable Diffusion, have remarkable generalization potential. However, training these models from scratch is a challenge because of the growing number of parameters.
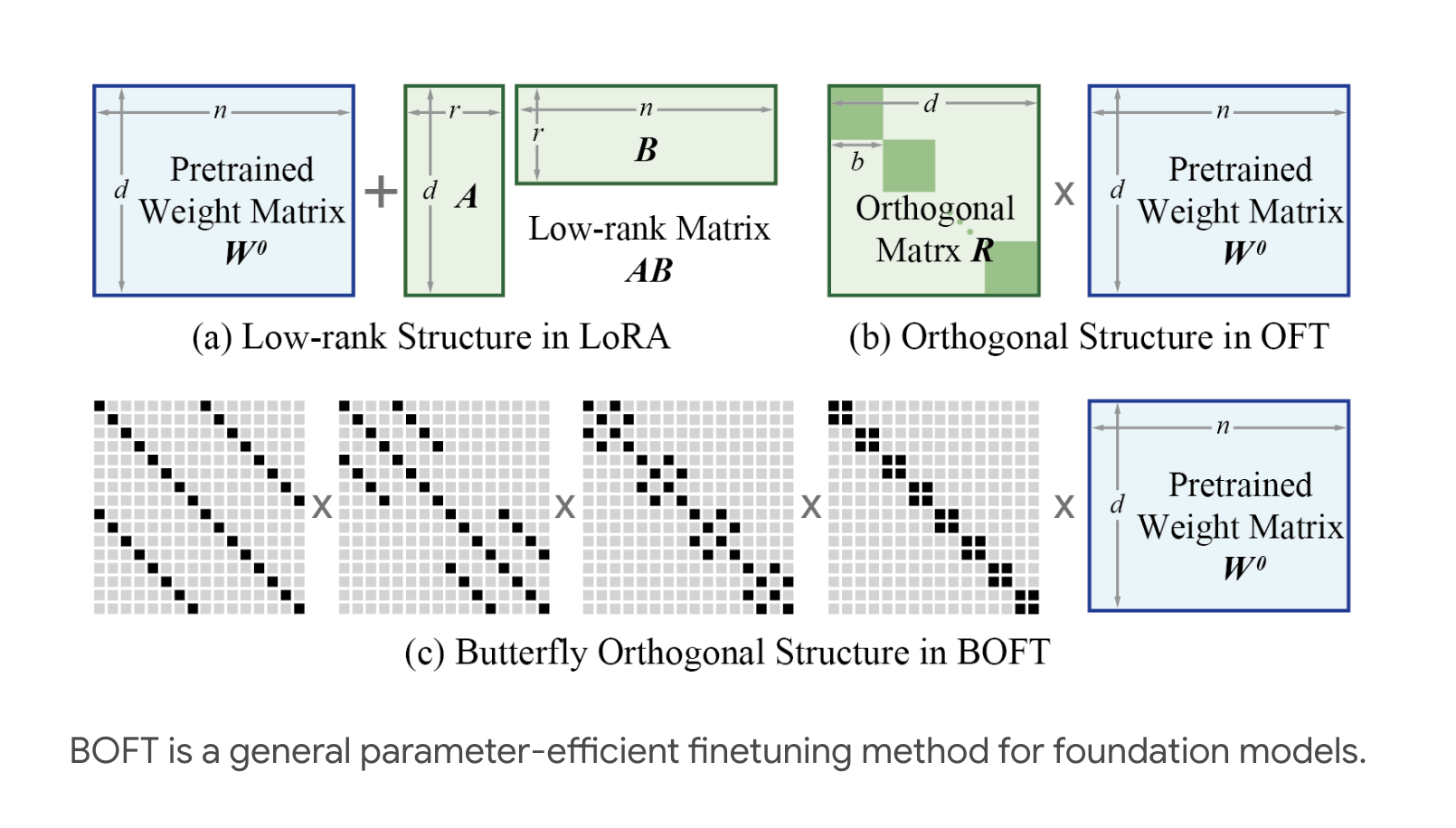
The approach of fine-tuning models is easy as it doesn’t involve any additional inference delay. However, the relational information of weight matrices is difficult to optimally maintain by conventional fine-tuning techniques, which have a low learning rate. Researchers have been studying the Orthogonal Fine-tuning (OFT) technique, which maintains pairwise angles between neurons during fine-tuning by transforming neurons in the same layer using the same orthogonal matrix. Though this technique has good potential, the same limitation arises, which is the enormous number of trainable parameters that arise from the high dimensionality of orthogonal matrices.
To overcome this challenge, a team of researchers has introduced Orthogonal Butterfly (BOFT), a unique and latest method that addresses parameter efficiency in Orthogonal Fine-tuning. Inspired by the butterfly structures in the Cooley-Tukey fast Fourier transform technique, BOFT produces a dense orthogonal matrix by assembling it with numerous factorized sparse matrices. In order to express the orthogonal matrix as a product of sparse matrices, computation time must be traded for space.
The team has shared that this technique can be understood by comparing it to an information transmission problem on a grid-structured graph, which makes it possible to use a variety of sparse matrix factorization techniques that preserve expressiveness while limiting trainable parameters. BOFT has been inspired by the butterfly graph of the Cooley-Tukey method, with its primary innovation being the butterfly factorization process.
With the use of this factorization, a dense matrix with a product of O(log d) sparse matrices, each with O(d) non-zero elements, can be created. BOFT can deliver efficient orthogonal parameterization with only O(d log d) parameters, a considerable reduction from the original OFT parameterization, by guaranteeing orthogonality for each sparse matrix. BOFT offers a general orthogonal fine-tuning framework and subsumes OFT.
The team has compared BOFT with the block-diagonal structure in OFT, and it has shown that in order to lower the effective trainable parameters, BOFT and OFT both add sparsity to orthogonal matrices. But for downstream applications, a smaller hypothesis class within the orthogonal group has been provided by BOFT’s butterfly structure, which allows for a smoother interpolation between full orthogonal group matrices and identity matrices. In order to emphasize that both low-rank and sparse matrices are families of structured matrices that achieve parameter efficiency, this structured approach has been compared with the low-rank structure in LoRA.
The researchers have summarized their primary contributions as follows.
- The problems of parameter efficiency in orthogonal fine-tuning have been studied to improve big models’ adaptability for downstream tasks.
- A new framework has been introduced for information transmission that reframes the challenge of constructing a parameter-efficient dense orthogonal matrix as an issue inside a grid-structured graph.
- Orthogonal Butterfly (BOFT), a parameter-efficient orthogonal fine-tuning method, has been introduced.
- Matrix factorization and theoretical explanations for why BOFT considerably lowers trainable parameters while preserving expressivity and training stability have been discussed.
- BOFT has outperformed the state-of-the-art techniques in adaption applications, demonstrating its superior parameter efficiency and generalization abilities.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.