This AI Research Introduces Flash-Decoding: A New Artificial Intelligence Approach Based on FlashAttention to Make Long-Context LLM Inference Up to 8x Faster
Large language models (LLMs) such as ChatGPT and Llama have garnered substantial attention due to their exceptional natural language processing capabilities, enabling various applications ranging from text generation to code completion. Despite their immense utility, the high operational costs of these models have posed a significant challenge, prompting researchers to seek innovative solutions to enhance their efficiency and scalability.
With the generation of a single response incurring an average cost of $0.01, the expenses associated with scaling these models to serve billions of users, each with multiple daily interactions, can quickly become substantial. These costs can escalate exponentially, particularly in complex tasks like code auto-completion, where the model is continuously engaged during the coding process. Recognizing the urgent need to optimize the decoding process, researchers have explored techniques to streamline and accelerate attention operation, a crucial component in generating coherent and contextually relevant text.
LLM inference, often called decoding, involves the generation of tokens one step at a time, with the attention operation being a significant factor in determining the overall generation time. While advancements like FlashAttention v2 and FasterTransformer have enhanced the training process by optimizing memory bandwidth and computational resources, the challenges during the inference phase persist. One of the major constraints encountered during decoding pertains to the scalability of the attention operation with longer contexts. As LLMs are increasingly tasked with handling more extensive documents, conversations, and codebases, the attention operation can consume a substantial amount of inference time, thus impeding the overall efficiency of the model.
Researchers introduced a groundbreaking technique called Flash-Decoding to address these challenges, building upon the foundation established by prior methodologies. The key innovation of Flash-Decoding lies in its novel approach to parallelization, which centers around the sequence length of keys and values. By strategically partitioning keys and values into smaller fragments, the approach allows for highly efficient utilization of the GPU, even with smaller batch sizes and extended contexts. Flash-Decoding significantly reduces the GPU memory requirements by leveraging parallelized attention computations and the log-sum-exp function, facilitating streamlined and efficient computation across the entire model architecture.
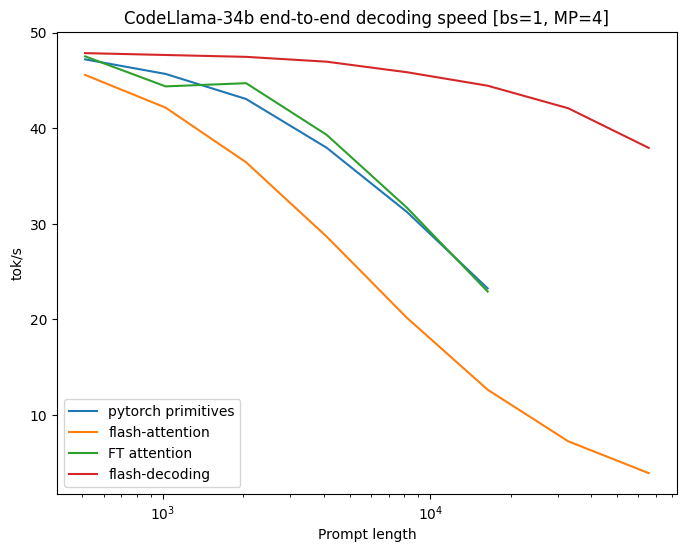
To evaluate the effectiveness of Flash-Decoding, comprehensive benchmark tests were conducted on the state-of-the-art CodeLLaMa-34b model, renowned for its robust architecture and advanced capabilities. The results showcased an impressive 8x enhancement in decoding speeds for longer sequences compared to existing approaches. Additionally, micro-benchmarks performed on the scaled multi-head attention for various sequence lengths and batch sizes further validated the efficacy of Flash-Decoding, demonstrating its consistent performance even as the sequence length was scaled up to 64k. This exceptional performance has played a pivotal role in significantly enhancing the efficiency and scalability of LLMs, marking a substantial advancement in large language model inference technologies.

In summary, Flash-Decoding has emerged as a transformative solution for addressing the challenges associated with attention operation during the decoding process for large language models. By optimizing GPU utilization and enhancing overall model performance, Flash-Decoding has the potential to substantially reduce operational costs and promote greater accessibility of these models across diverse applications. This pioneering technique represents a significant milestone in large language model inference, paving the way for heightened efficiency and accelerated advancements in natural language processing technologies.
Check out the Reference Page and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.
Credit: Source link
Comments are closed.