This AI Research Introduces LISA: Large Language Instructed Segmentation Assistant that Inherits the Language Generation Capabilities of the Multi-Modal Large Language Model (LLM)
Imagine you want to have coffee, and you instruct a robot to make it. Your instruction involves “ Make a cup of coffee “ but not step-by-step instructions such as “ Go to the kitchen, find the coffee machine, and switch it on.” Present existing systems contain models that rely on human instructions to identify any targeted object. They lack the ability of reasoning and active comprehension of the user’s intentions. To tackle this, researchers at Microsoft Research, the University of Hong Kong, and SmartMore propose a new task called reasoning segmentation. This self-reasoning ability is crucial in developing next-generation intelligent perception systems.
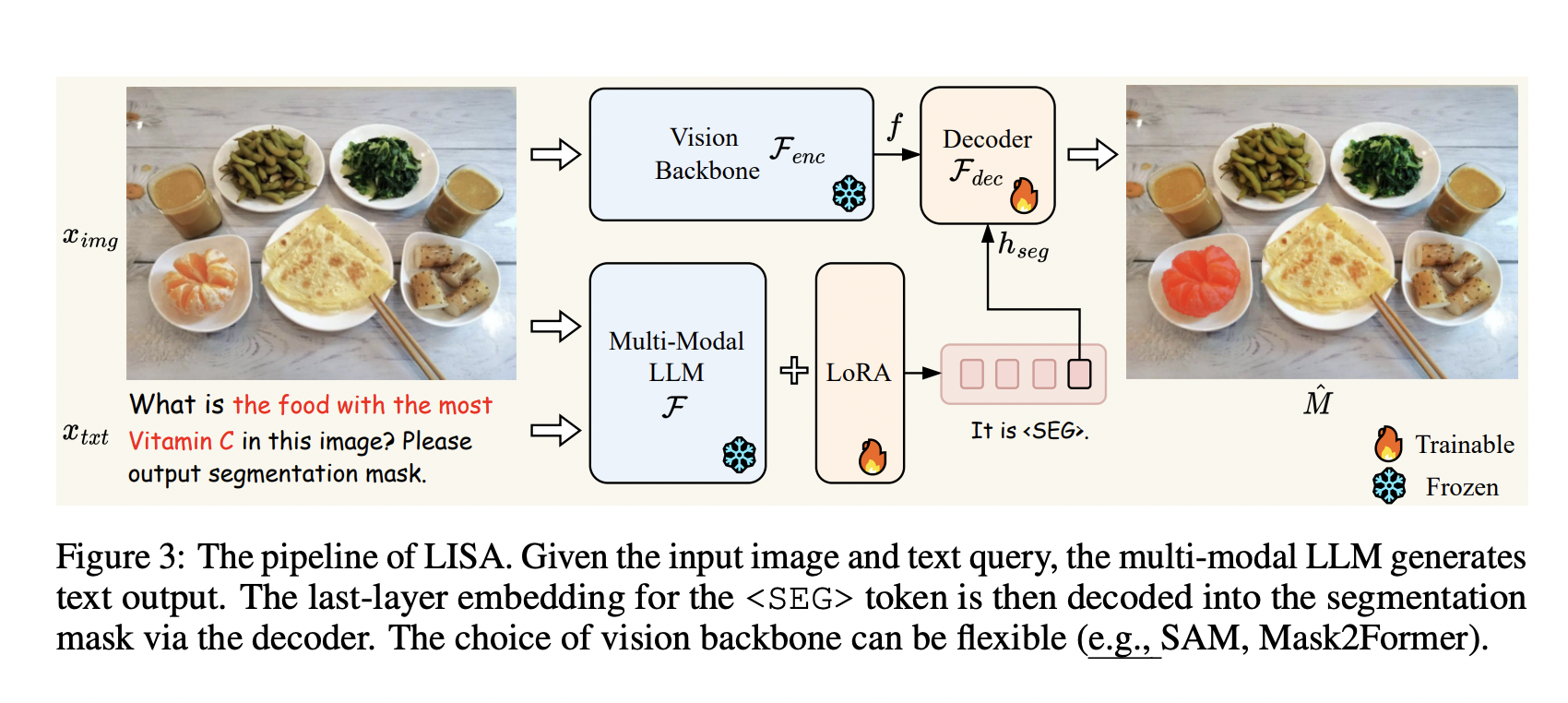
Reasoning segmentation involves designing the output as a segmentation mask for a complex and implicit query text. They also create a benchmark comprising over a thousand image-instruction pairs with reasoning and world knowledge for evaluation. They built an assistant similar to Google Assistant and Siri called Language Instructed Segmentation Assistant ( LISA ). It inherits the language generation capabilities of the multi-modal Large Language Model while processing the ability to produce segmentation tasks.
LISA can handle complex reasoning, world knowledge, explanatory answers, and multi-conversations. Researchers say their model can demonstrate robust zero-shots when trained on reasoning-free datasets. Fine-tuning their model with just 239 reasoning segmentation image-instruction pairs resulted in an enhancement of the performance.
The reasoning segmentation task differs from the previous referring segmentation, which requires the model to possess reasoning ability or access world knowledge. Only by completely understanding the query the model can well perform the task. Researchers say their method unlocks new reasoning segmentation, which proves effective compared to complex and standard reasoning.
The researcher used the training dataset, which does not include any reasoning segmentation sample. It contained only the instances where the target objects were explicitly indicated in the query test. Even without the complex reasoning training dataset, they found that LISA demonstrated impressive zero-shot ability on ReasonSeg ( the benchmark ).
Researchers find that LISA accomplishes complex reasoning tasks with more than a 20% gIoU performance boost. Where gIoU is the average of all per-image Intersection-over-Unions (IoUs). They also find that the LISA-13B outperforms the 7B with long query scenarios. This implies that a stronger multi-modal LLM might lead to even better results in performance. Researchers also show that their model is competent with vanilla referring segmentation tasks.
Their future work will emphasize more on the importance of self-reasoning ability, which is crucial for building a genuinely intelligent perception system. Establishing a benchmark is essential for evaluation and encourages the community to develop new techniques.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.