This AI Research Presents a New Approach to Pose Object Recognition as Next Token Prediction
How can we effectively approach object recognition? A team of researchers from Meta AI and the University of Maryland tackled the problem of object recognition by developing a new method that utilizes a language decoder to predict text tokens from image embeddings and form labels. They also proposed a strategy to create a more efficient decoder without compromising performance.
Object recognition, predating the deep learning era, has aided in image annotation. Methods involved region slicing and word prediction, aligning regions with words using lexicons. Co-embedding images and text in a shared space addressed image-text matching, emphasizing phrase grounding. Image annotation evolved from topic models to transformer-based architectures. Language models like GPT and LLaMA contributed to visual perception and were applied in detection, few-shot recognition, explanations, and reasoning. Architectural concepts from language models, such as the prefix idea, have influenced and been explored in the vision-language domain.
The study tackles object recognition in computer vision by introducing a framework with an image encoder producing embeddings and a language decoder predicting object labels. Unlike traditional methods with fixed embeddings, the proposed approach treats recognition as the next token prediction, enabling auto-regressive decoding of tags from image embeddings. It eliminates the need for predefined labels, fostering flexible and efficient recognition. Key innovations, including a non-causal attention mask and a compact decoder, enhance efficiency without compromising performance, offering a novel solution to object recognition in computer vision.
The research presents an object recognition approach based on next-token prediction, using a language decoder that predicts text tokens from image embeddings to create labels. Auto-regression is employed, incorporating a non-causal attention mask for the decoder to model tokens independently and treat image tokens as a prefix. It introduces one-shot sampling for parallel token sampling from multiple labels, ranking them by probabilities during inference. For efficiency, a compact decoder construction strategy is proposed, involving the removal of intermediate blocks from a pretrained language model while preserving performance.
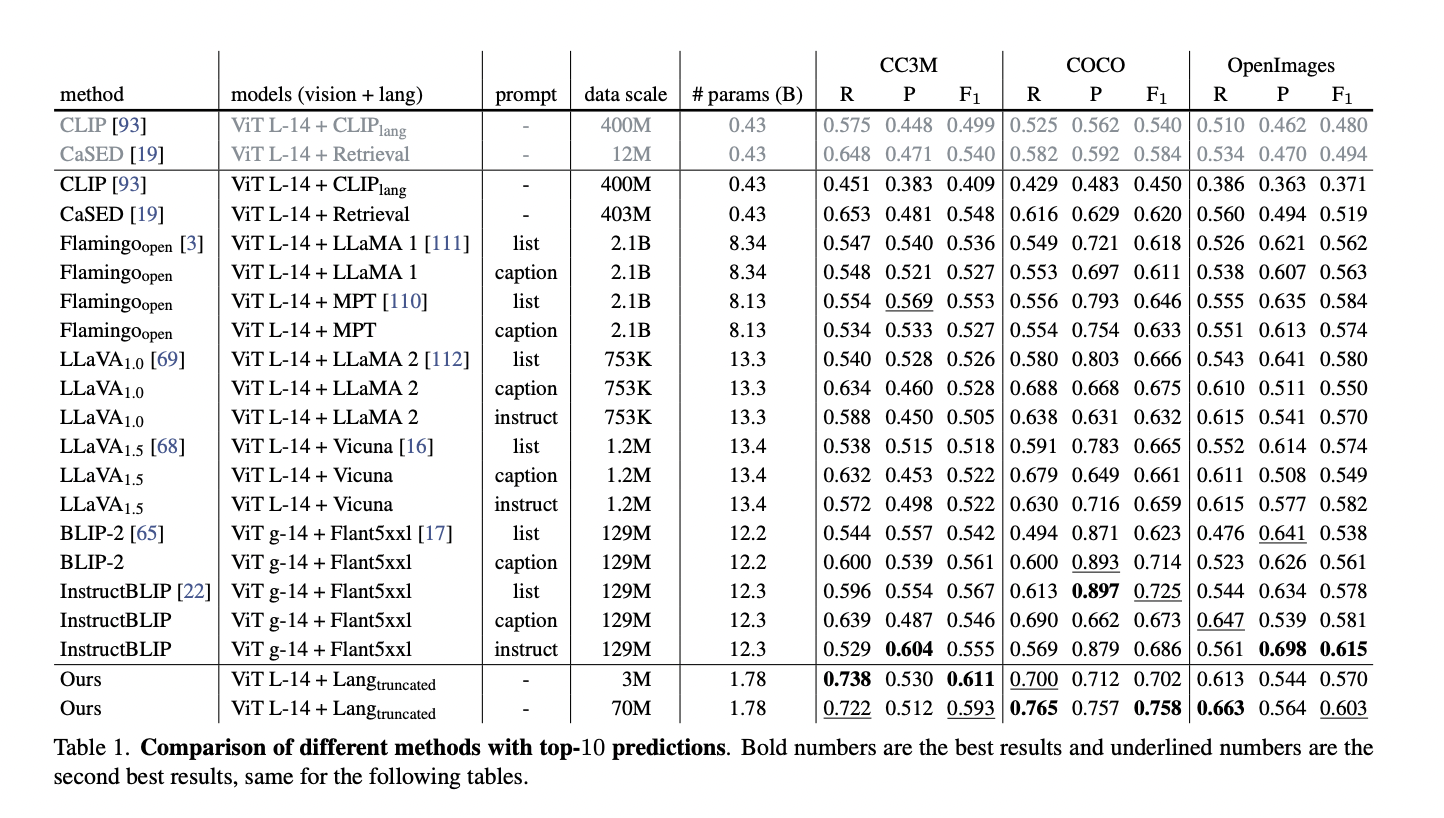
The study thoroughly compares with CLIP, Open Flamingo, LLaVA, BLIP-2, InstructBLIP, and CaSED, evaluating top-k predictions and precision-recall curves. The proposed approach consistently outperforms competitors for top-10 predictions, indicating superior relevance in label generation. Precision-recall curves exhibit a strong linear correlation, suggesting better prediction quality across datasets, with higher recall as k increases. Ablation studies on decoder truncation show a minimal performance drop on CC3M but no change on COCO and OpenImages. It underscores the importance of initial LLaMA 7B model blocks for object recognition, leading to removing blocks after the 11th for a more compact decoder.
In conclusion, the proposed auto-regressive approach utilizing next-token prediction for object recognition outperforms other methods in generating top-10 predictions across datasets, indicating superior relevance in label generation. The strong linear correlation observed in precision-recall curves suggests better prediction quality across all test datasets. Ablation studies on decoder truncation show a slight performance drop on CC3M but no change on COCO and OpenImages. Also, removing intermediate transformer blocks in the LLaMA model results in a more compact decoder with comparable performance, highlighting the importance of a subset of knowledge in LLMs for object recognition.
Further research could focus on addressing competition concerns in one-shot sampling by exploring mitigation strategies. Another potential avenue is to investigate the direct alignment of generative models, particularly LLMs, with object recognition without predefined subsets or reference pivots. Further, it would be useful to examine the impact of significantly increasing the volume of training data to reduce reliance on interpreting or recognizing unseen data and concepts, which aligns with the open-world paradigm of incrementally learning new labels over time.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.