This AI Research Presents Lucene Integration for Powerful Vector Search with OpenAI Embeddings
Lately, there have been significant strides in applying deep neural networks to the search field in machine learning, with a specific emphasis on representation learning within the bi-encoder architecture. In this framework, various types of content, including queries, passages, and even multimedia, such as images, are transformed into compact and meaningful “embeddings” represented as dense vectors. These dense retrieval models, built on this architecture, serve as the cornerstone for enhancing retrieval processes within large language models (LLMs). This approach has gained popularity and proven to be highly effective in enhancing the overall capabilities of LLMs within the broader realm of generative AI today.
The narrative suggests that due to the need to handle numerous dense vectors, enterprises should incorporate a dedicated “vector store” or “vector database” into their “AI stack.” A niche market of startups is actively promoting these vector stores as innovative and essential components of contemporary enterprise architecture. Notable examples include Pinecone, Weaviate, Chroma, Milvus, and Qdrant, among others. Some proponents have even gone so far as to propose that these vector databases could eventually supplant the longstanding relational databases.
This paper presents a counterpoint to this narrative. The arguments revolve around a straightforward cost-benefit analysis, considering that search represents an existing and established application in many organizations, leading to significant prior investments in these capabilities. The production infrastructure is dominated by the broad ecosystem centered around the open-source Lucene search library, most notably driven by platforms such as Elasticsearch, OpenSearch, and Solr.
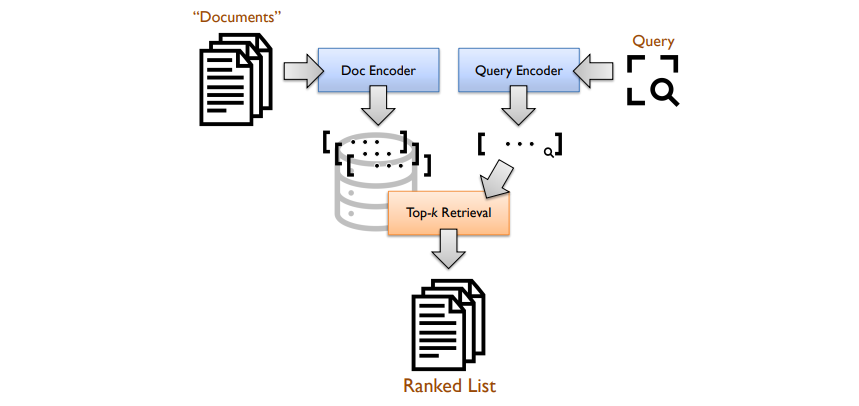
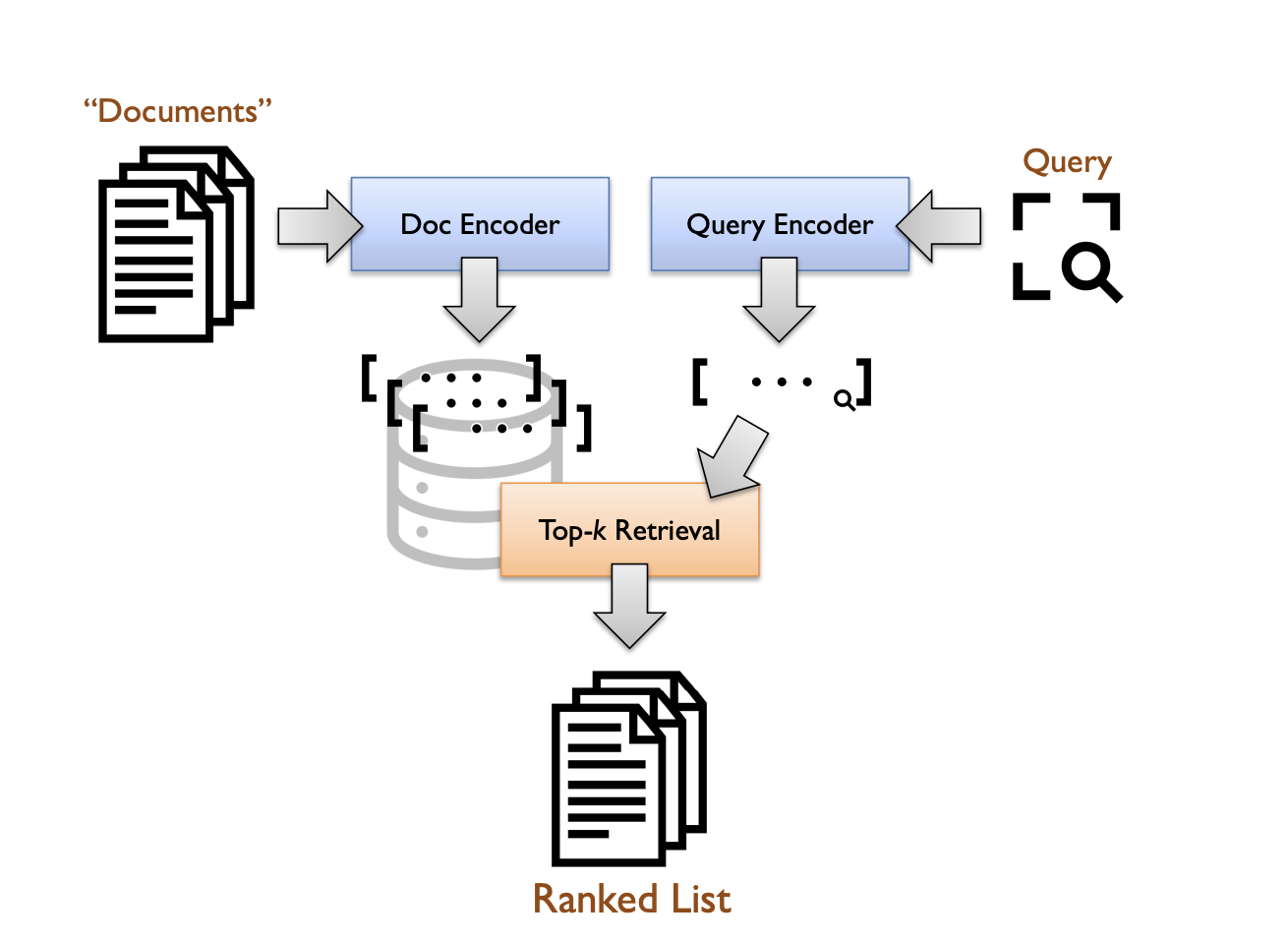
The above image shows a standard bi-encoder architecture, where encoders generate dense vector representations (embeddings) from queries and documents (passages). Retrieval is framed as a k-nearest neighbor search in vector space. The experiments focused on the MS MARCO passage ranking test collection, built on a corpus comprising approximately 8.8 million passages extracted from the web. The standard development queries and queries from the TREC 2019 and TREC 2020 Deep Learning Tracks were used for evaluation.
The findings suggest that it is possible today to build a vector search prototype using OpenAI embeddings directly with Lucene. The growing popularity of embedding APIs supports our arguments. These APIs simplify the complex process of generating dense vectors from content, making it more accessible to practitioners. Indeed, Lucene is all you need when you are building search ecosystems today. But as it happens, only time will tell if you are right. Finally, this reminds us that weighing costs vs. benefits will remain a primary mindset, even in the rapidly evolving AI world.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.