This AI Research Proposes DISC-MedLLM: A Comprehensive Solution that Leverages Large Language Models (LLMs) to Provide Accurate Medical Response
The rise of telemedicine has changed how healthcare is provided, opening up professional networks, lowering prices, and allowing for distant medical consultations. Additionally, intelligent medical systems have improved online medical services by adding capabilities like medical information extraction, drug recommendations, automated diagnosis, and health question answering. While there has been progress in constructing intelligent healthcare systems, earlier research has concentrated on particular problems or illnesses with narrow applications, leaving a gap between experimental developments and real-world usage. To close this gap, complete solutions for a wider range of medical scenarios and end-to-end conversational healthcare services of the highest caliber for consumers are required.
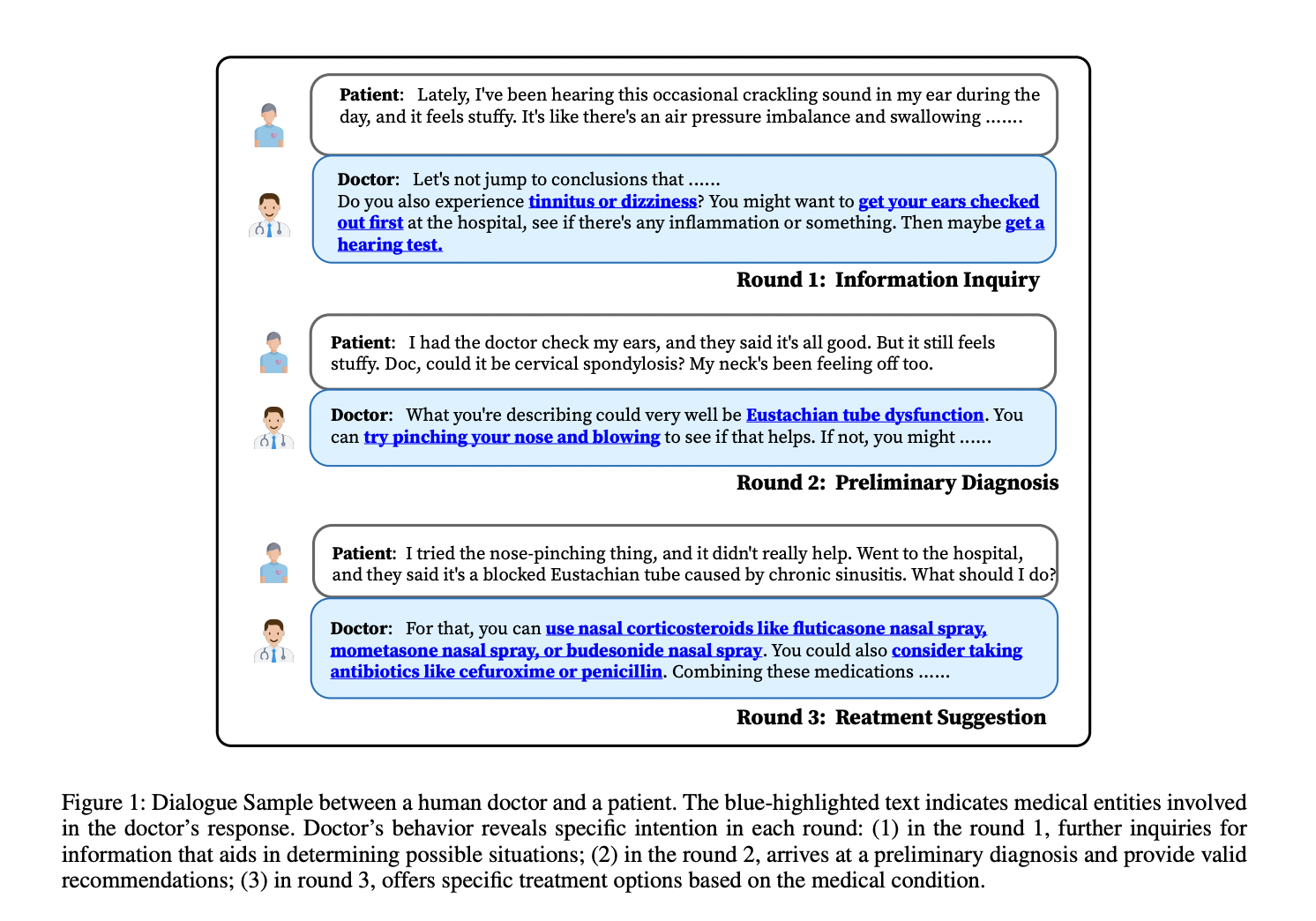
Large Language Models have recently demonstrated an astonishing capacity for conversing meaningfully and following instructions from humans. These advancements have created new opportunities for developing systems for medical consulting. However, circumstances involving medical consultations are typically complex and outside the scope of LLMs from the general area. Figure 1 depicts an illustration of a real-world medical consultation. It exhibits two qualities. To begin with, one needs thorough and trustworthy medical knowledge to comprehend the conversation and respond appropriately at each stage. General domain LLMs provide output unrelated to the particular case, exposing major hallucination concerns.
Second, it often takes several rounds of talk to get enough knowledge about the patient to provide healthcare consultation, and each conversational round has a defined goal. However, broad-domain LLMs often have limited multi-turn querying skills on the specifics of a user’s health status and are single-turn agents. Based on these two findings, researchers from Fudan University, Northwestern Polytechnical University and University of Toronto contend that medical LLMs should encode thorough and trustworthy medical knowledge while conforming to the distribution of real-world medical conversation. Inspired by the success of Instruction Tuning, they investigate how to build high-quality Supervised Fine-tuning datasets for training medical LLMs and include knowledge of medicine and patterns of consultation behavior.
In actual practice, they create samples using three different methods:
• The development of medical knowledge graph-driven samples. Following a patient query distribution collected from a real-world consultation dataset, they pick knowledge triples from a medical knowledge network using a department-oriented approach. GPT-3.5 is used to few-shot create QA pairings for each triple. There are 50k samples as a result.
• Reconstruction of real-world dialogue. For improving LLMs, consultation records gathered from medical forums are suitable sources. The language used in these documents is casual, the terminology is presented inconsistently, and various healthcare practitioners have varied expressive styles. As a result, they use GPT-3.5 to recreate the discussion using actual cases. There are 420k samples as a result.
• After sample collection, human preference. They manually choose a limited group of entries from the real-world medical discourse records spanning various consultation settings and rewrite certain examples for alignment with human intention. They additionally guarantee the overall quality of each discussion after the human-guided reconstruction. There are 2k samples as a result. DISC-MedLLM is then trained using the newly created SFT datasets using a two-stage training process on top of a general domain Chinese LLM with 13B parameters 1. They evaluate the model’s performance from two angles to determine its capacity to offer systematic consultation in multi-turn discussions and accurate replies in single-turn dialogues.
They build a benchmark of multiple choice questions gathered from three public medical datasets and assess the model’s accuracy using this benchmark for single-turn evaluation. For a multi-turn review, they first create a small collection of excellent consultation cases, using GPT-3.5 to simulate a patient and converse with the model. They assess the model’s proactiveness, accuracy, helpfulness, and linguistic quality using GPT-4. The experimental findings show that, although falling short of GPT-3.5, DISCMedLLM beats the medical large-scale HuatuoGPT with identical parameters by an average of over 10%.
Additionally, DISC-MedLLM performs better overall in simulated medical consultation settings than baseline models like GPT-3.5, HuatuoGPT, and BianQue. DISC-MedLLM outperforms other Chinese medical LLMs, particularly in cases involving medical departments and patient intentions.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.