This AI Research Proposes FireAct: A Novel Artificial Intelligence Approach to Fine-Tuning Language Models with Trajectories from Multiple Tasks and Agent Methods
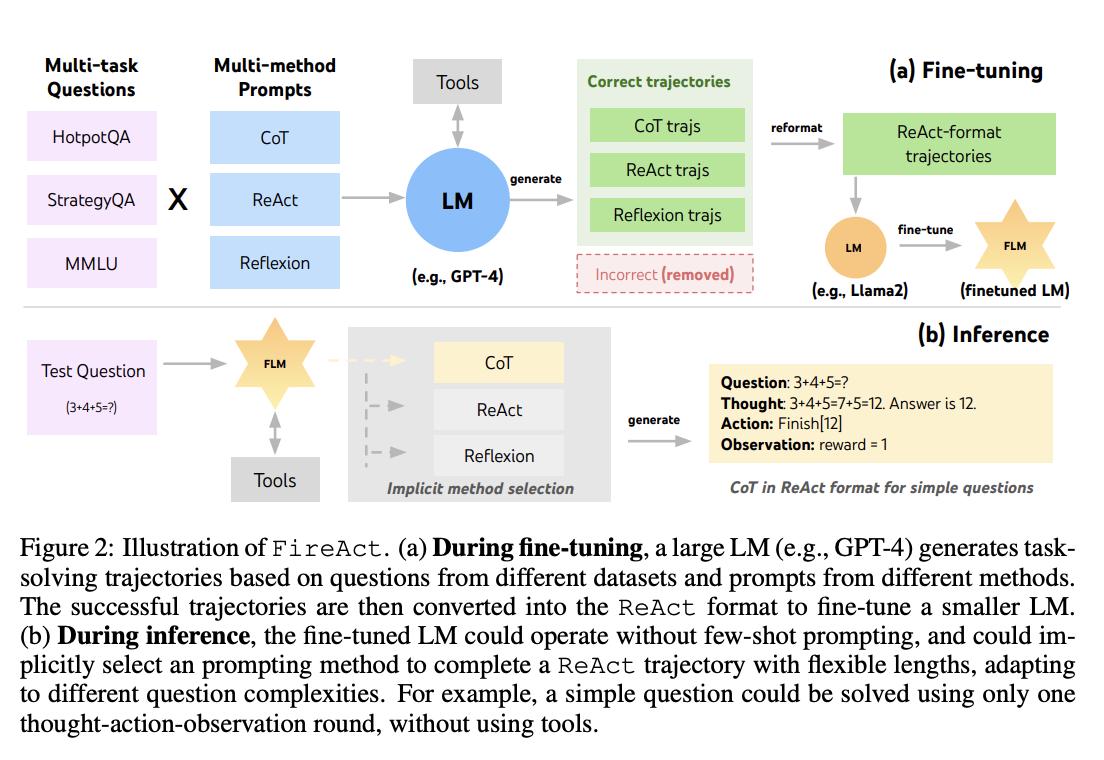
Fine-tuning language models are often overlooked to create language agents, specifically focusing on enhancing their capabilities in question-answering tasks using the Google search API. Researchers from System2 Research, the University of Cambridge, Monash University, and Princeton University show that fine-tuning backbone language models consistently boosts the performance of these agents. Their research introduces “FireAct,” a fine-tuning approach incorporating trajectories from multiple tasks and prompting methods, underscoring the significance of diverse fine-tuning data in refining language agents.
Their research delves into the intersection of language agents and fine-tuning pre-trained language models. While prior research has explored language agents and fine-tuning separately, this study bridges the gap. FireAct, a fine-tuning approach for language agents, systematically investigates the advantages and consequences of fine-tuning language models for these agents. Their inquiry includes examining scaling effects, robustness, generalization, efficiency, and cost implications, contributing valuable insights to this emerging field.
Their method addresses the need for more effective language agents by introducing a systematic approach to fine-tuning language models (LMs) for these agents. Existing language agents rely on basic LMs and limited-shot prompting techniques, resulting in performance and robustness constraints. Experimental results reveal that fine-tuning LMs significantly enhances agent performance, reduces inference time, and improves robustness, offering a promising avenue for real-world applications.
Their study explores the fine-tuning of LMs for language agents, particularly in question answering (QA) with a Google search API. Experiments focus on LMs, data sizes, and fine-tuning methods, with performance evaluated using metrics like HotpotQA EM. Their approach demonstrates the advantages of fine-tuning in terms of improved performance, efficiency, robustness, and generalization over traditional prompting methods.
Fine-tuning LMs for language agents yields significant performance improvements, with a 77% boost in HotpotQA performance using Llama2-7B and 500 agent trajectories from GPT-4. The CoT method enhances answer quality. Mixed agent methods consistently improve performance, aligning with baseline ranges. Fine-tuning increases precision, enhancing exact answers and overall answer quality, reflected in EM and F1 scores. However, F1 scores plateau and dip beyond four epochs, indicating diminishing returns on extended fine-tuning.
Integration of the CoT method further elevates answer quality. The FireAct approach, involving fine-tuning with diverse task trajectories and prompts, further enhances agent performance. Language agents that rely solely on off-the-shelf LMs face limitations, such as a fixed set of task-solving trajectories, tool overuse, and deviation recovery challenges. Future research on calibration and meta-reasoning could improve agent designs, addressing tool usage and reflection challenges.
Research questions stemming from FireAct suggest expanding fine-tuning LMs for language agents into diverse tasks, grounding setups, and domains. Investigations should encompass API tool usage, web exploration, and real-world integration. Exploring various fine-tuning data sources and techniques is crucial for enhancing agent performance. The impact of calibration and meta-reasoning on agent designs and their ability to manage tool usage and trajectory deviations should be addressed. Finally, comprehensive studies are needed to assess scalability, robustness, efficiency, and cost implications.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.