This AI Research Proposes TeCH to Reconstruct a Lifelike 3D Clothed Human from a Single Image with Detailed Full-Body Geometry and High-Quality Texture
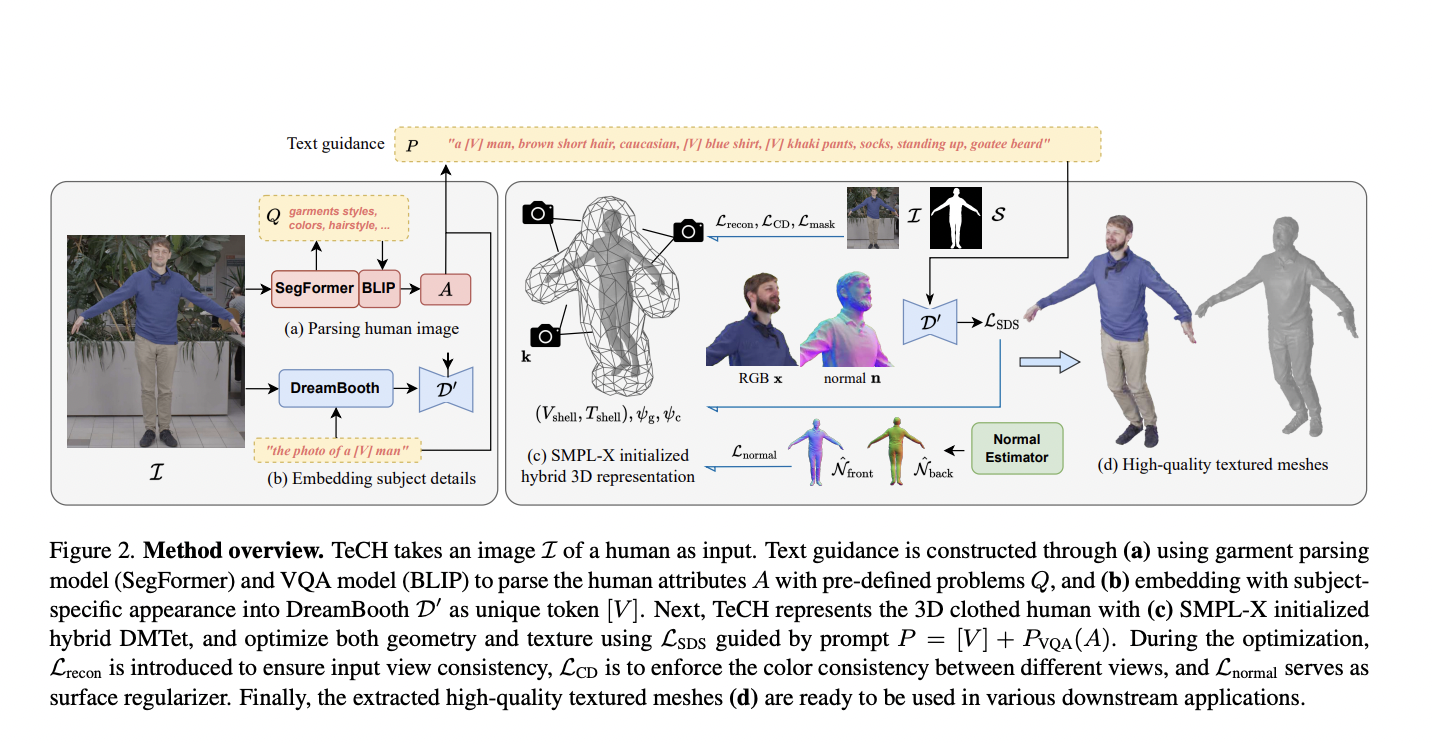
High-fidelity For many augmented and virtual reality applications, including gaming, social networking, education, e-commerce, and immersive telepresence, 3D digital persons are essential. Many methods concentrate on reconstructing a 3D clothed human figure from a single photograph to make it easier to create digital humans from readily available in-the-wild photos. However, the absence of observations of non-visible locations makes this problem seem poorly posed despite the advances achieved by earlier techniques. It has failed to forecast invisible parts (like the backside) using obvious visual cues (such as colors and normal estimations), which has led to hazy texture and smoothed-out geometry. As a result, while looking at these reconstructions from various perspectives, discrepancies appear. Multi-view supervision is a viable answer to this problem. But is it possible with just one image as an input? Here, they suggest TeCH as a potential solution. Tech blends textual information acquired from the input picture with a customized Text-to-picture diffusion model, i.e., DreamBooth, to guide the reconstruction process, in contrast to past research that primarily studies the relationship between apparent frontal signals and non-visual areas.
They specifically separate the semantic information from the single input image into the distinctive and finely detailed look of the topic, which is difficult for words to describe correctly:
1) Using a garment parsing model (i.e., SegFormer) and a pre-trained visual-language VQA model (i.e., BLIP), explicit parsing of descriptive semantic prompts from the input image is performed. These prompts include specific descriptions of colors, clothing styles, haircuts, and facial traits.
2) A customized Text-to-Image (T2I) diffusion model embeds indescribable appearance information, which implicitly determines the subject’s distinctive look and fine-grained characteristics, into a special token “[V]”. They use multi-view Score Distillation Sampling (SDS), reconstruction losses based on the original observations, and regularisation obtained from off-the-shelf normal estimators to optimize the 3D human based on these information sources to improve the fidelity of the reconstructed 3D human models while maintaining their original identity.

Researchers from Zhejiang University, Max Planck Institute for Intelligent Systems, Mohamed bin Zayed University of Artificial Intelligence, and Peking University suggest a hybrid 3D representation based on DMTet to express a high-resolution geometry at a reasonable price. To accurately depict the general form of the body, our hybrid 3D representation combines an explicit tetrahedral grid with implicit RGB and Signed Distance Function (SDF) fields. They first optimize this tetrahedral grid, extract the geometry represented as a mesh, and then optimize the texture in a two-stage optimization procedure. Tech makes it possible to recreate accurate 3D models of clothed people with precise full-body geometry and rich textures with a unified color scheme and pattern.
As a result, it makes it easier for numerous downstream applications, including character animation, novel view rendering, and shape & texture manipulation. Tech has proven to be more effective at recreating geometric features in quantitative tests on 3D-clothed human datasets that encompass a variety of postures (CAPE) and attire (THuman2.0). Tech outperforms SOTA approaches regarding rendering quality, according to qualitative assessments done on real-world photos and perceptual research. The code will be publicly accessible for research purposes.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, please follow us on Twitter
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.