This AI Research Unveils LSS Transformer: A Revolutionary AI Approach for Efficient Long Sequence Training in Transformers
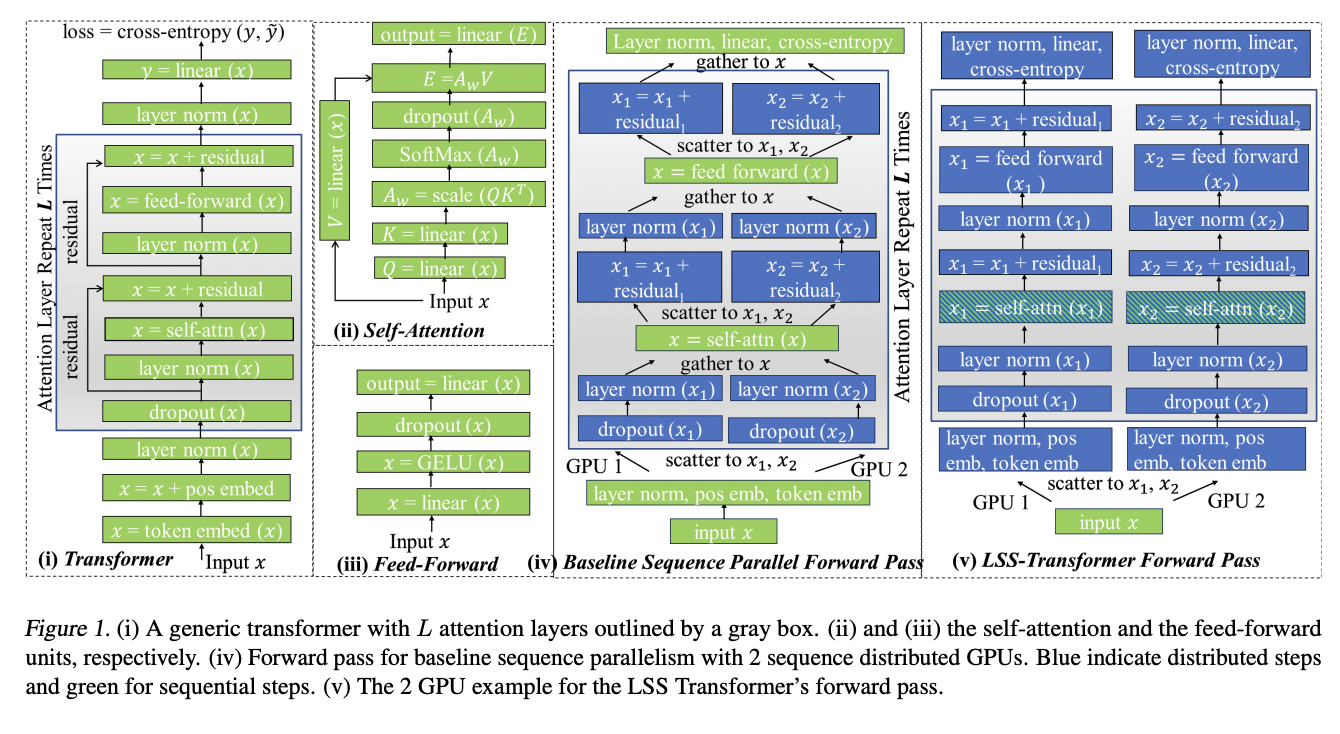
A new AI research has introduced the Long Short-Sequence Transformer (LSS Transformer), an efficient distributed training method tailored for transformer models with extended sequences. It segments long sequences among GPUs, with each GPU handling partial self-attention computations. LSS Transformer employs fused communication and a unique double gradient averaging technique to minimize transmission overhead, resulting in impressive speedups and memory reduction, surpassing other sequence parallel methods. Performance evaluation on the Wikipedia enwik8 dataset shows that the LSS Transformer achieves faster training and improved memory efficiency on multiple GPUs, outperforming Nvidia’s sequence parallelism.
The transformer, known for its self-attention mechanism, is a powerful neural network architecture used in natural language and image processing. Training transformers with longer sequences enhances contextual information grasp and prediction accuracy but increases memory and computational demands. Various approaches have been explored to address this challenge, including hierarchical training, attention approximation, and distributed sequence parallelism.
The LSS Transformer outperformed state-of-the-art sequence parallelism on 144 Nvidia V100 GPUs by achieving 5.6 times faster training and 10.2 times improved memory efficiency on the Wikipedia enwik8 dataset. It demonstrated remarkable scalability, handling an extreme sequence length of 50,112 with 3,456 GPUs, attaining 161% super-linear parallel efficiency and a substantial throughput of 32 petaflops. In the context of weak scaling performance, the LSS Transformer exhibited superior scalability and reduced communication compared to other sequence parallel methods. In a large model experiment involving 108 GPUs, it maintained a high scaling efficiency of 92 and showcased a smaller memory footprint when contrasted with baseline parallelism. The LSS Transformer also excelled with a computation throughput of 8 petaflops at 144 nodes for a sequence length 50,112, surpassing baseline sequence parallelism in speed and scalability.
The LSS Transformer presents a groundbreaking solution to the challenge of training transformer models on lengthy sequences, delivering remarkable speed enhancements and memory efficiency while minimizing communication overhead. This distributed training method segments sequences across GPUs, utilizing fused communication and double gradient averaging. The LSS Transformer’s ability to facilitate ultra-long sequence training makes it a valuable asset for applications requiring extensive token dependencies, such as DNA sequence analysis, lengthy document summarization, and image processing.
The study has some limitations. First, it needs to be compared with existing methods for long sequence training, focusing on Nvidia sequence parallelism. Second, an in-depth examination of the trade-offs between accuracy and efficiency achieved by the LSS Transformer is needed. Third, it needs to address potential real-world implementation challenges. Fourth, it does not explore the influence of varying hyperparameters or architectural modifications on the LSS Transformer’s performance. Lastly, there is no comprehensive comparison with approximation-based approaches for reducing computation and memory usage.
Future research directions for the LSS Transformer include:
- Evaluating its performance and scalability across diverse datasets and tasks.
- Extending its applicability to various transformer models, for example, encoder-only or decoder-only.
- Optimizing for larger sequence lengths and more GPUs to enhance ultra-long sequence training.
- Refining techniques for handling intertoken dependencies in an efficient and parallelized manner.
- Integrating the LSS Transformer into established deep learning frameworks to improve accessibility for researchers and practitioners.
These efforts can broaden its utility and adoption in the field.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.