This AI Study Proposes a Fast and High-Quality Neural Vocoder Called ‘WaveFit,’ Which Integrates the Essence of GANs into a DDPM-like Iterative Framework
Neural vocoders are artificial neural networks that use auditory data to produce a voice waveform. They are essential components of modern speech-generating applications. They are employed as the backbone module in text-to-speech (TTS), voice conversion, speech-to-speech translation (S2ST), speech enhancement (SE), speech restoration, and speech coding, among other applications. Autoregressive (AR) models were the first to transform the quality of voice creation. However, because they need a significant number of sequential operations to generate, parallelizing the calculation is complex, and their processing time is sometimes much longer than the period of the output signals. Non-AR models have gained popularity for speeding up inference because of their parallelization-friendly model topologies.
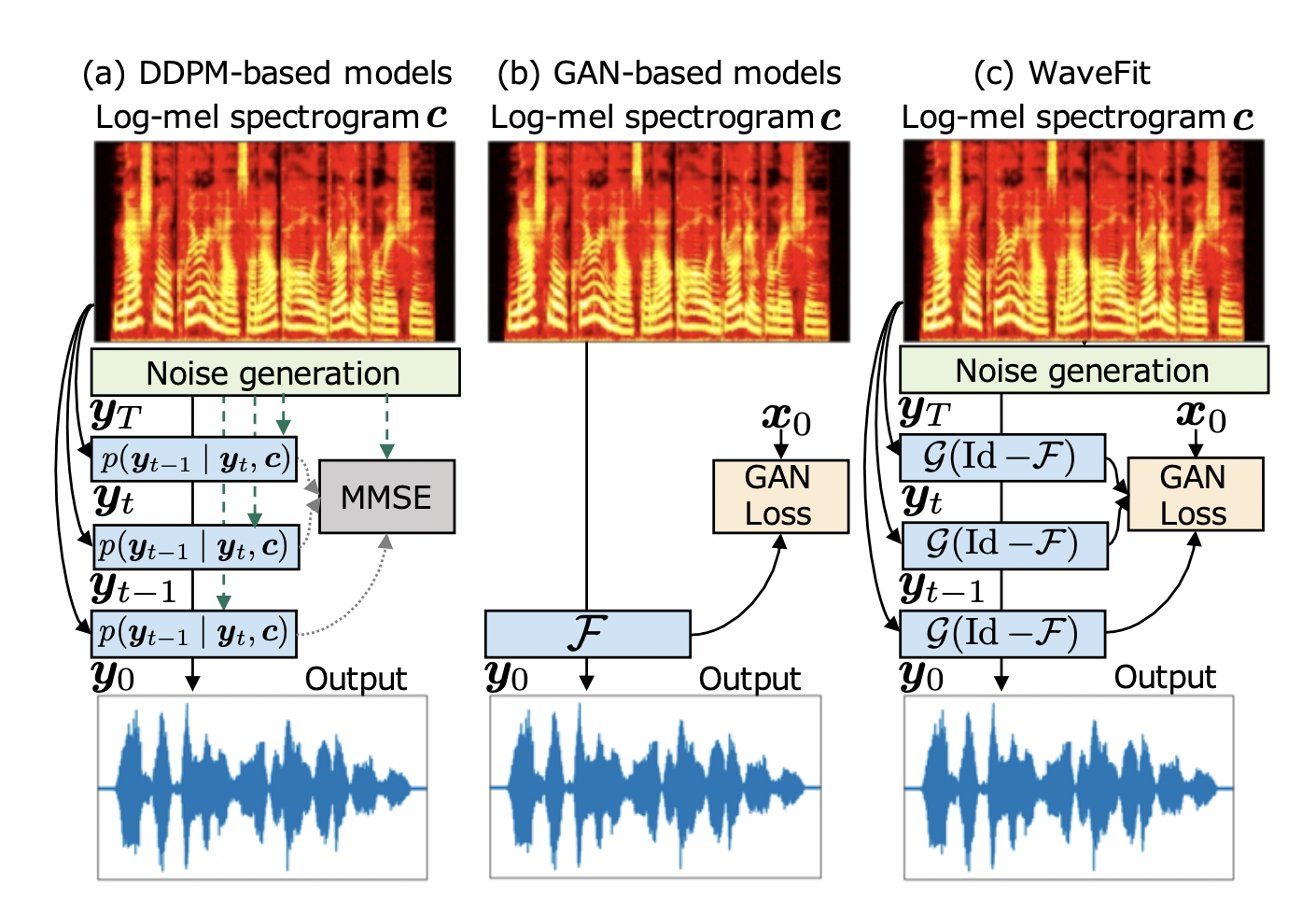
Early investigations of non-AR models relied on normalizing flows that used layered invertible deep neural networks (DNNs) to transform input noise into speech. In recent years, the most successful non-AR solution has been using generative adversarial networks (GANs). They are trained to create address waveforms indistinguishable from natural human speech through discriminator networks. The denoising diffusion probabilistic model (DDPM) is the most recent member of the generative models for neural vocoders. It turns random noise into a voice waveform via an iterative sampling process, as shown in Figure below.
Because a DDPM-based neural vocoder continually refines speech waveform, there is a trade-off between sound quality and computing cost, requiring tens of iterations to obtain high-fidelity speech waveform. DDPMs may develop speech waveforms equivalent to AR models after hundreds of iterations. Existing DDPM research has studied the inference noise schedule, the usage of adaptive prior, the network design, and the training technique to minimize the number of iterations while retaining quality. However, producing a speech waveform with the same quality as natural human speech in a few cycles remains difficult.
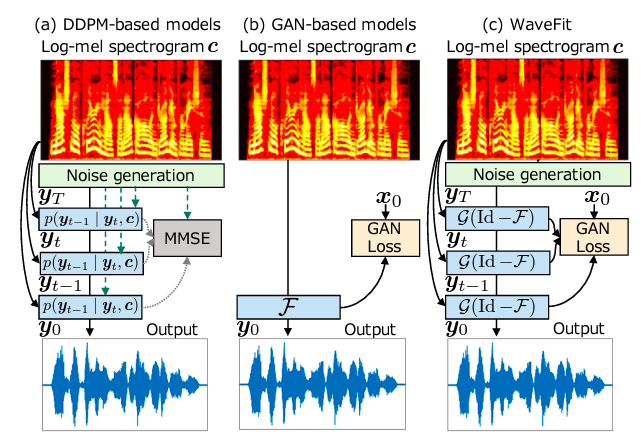
Recent research has shown that the essence of DDPMs and GANs may coexist. Denoising diffusion GANs employ a generator to predict a clean sample from a diffused one and a discriminator to distinguish diffused models from clean or predicted ones. The approach was used in TTS precisely to predict a log-mel spectrogram given text input. This was done as DDPMs and GANs can be joined in various ways, and a novel combination will emerge that can achieve high-quality synthesis in a limited number of rounds. Researchers introduce WaveFit, an iterative-style non-AR neural vocoder trained to utilize a GAN-based loss. It is based on the fixed-point iteration idea.

The proposed approach uses a DNN as a denoising mapping to eliminate noise components from an input signal, bringing the output closer to the target speech. They employ a loss insensitive to imperceptible phase variations by combining a GAN-based and a short-time Fourier transform (STFT)-based loss. The intermediate output signals are encouraged to approach the target speech with the iterations by combining the loss for all iterations. Subjective hearing tests revealed that WaveFit could produce a higher-quality speech waveform than traditional DDPM models. The trials also showed that the audio quality of WaveFit’s synthetic speech after five iterations is equivalent to that of WaveRNN and natural human speech. Multiple examples can be found on the website of WaveFit.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'WAVEFIT: AN ITERATIVE AND NON-AUTOREGRESSIVE NEURAL VOCODER BASED ON FIXED-POINT ITERATION'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.