This Artificial Intelligence (AI) Paper From South Korea Proposes FFNeRV: A Novel Frame-Wise Video Representation Using Frame-Wise Flow Maps And Multi-Resolution Temporal Grids

Research on neural fields, which represent signals by mapping coordinates to their quantities (e.g., scalars or vectors) with neural networks, has exploded recently. This has sparked an increased interest in utilizing this technology to handle a variety of signals, including audio, image, 3D shape, and video. The universal approximation theorem and coordinate encoding techniques provide the theoretical foundations for accurate signal representation of brain fields. Recent investigations have shown its adaptability in data compression, generative models, signal manipulation, and basic signal representation.
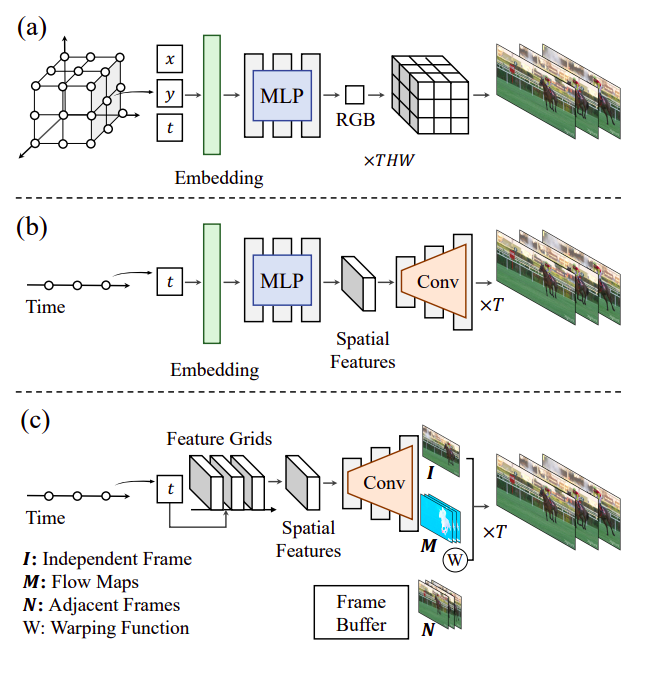
Research on neural fields, which represent signals by mapping coordinates to their quantities (e.g., scalars or vectors) with neural networks, has exploded recently. This has sparked an increased interest in utilizing this technology to handle a variety of signals, including audio, image, 3D shape, and video. The universal approximation theorem and coordinate encoding techniques provide the theoretical foundations for accurate signal representation of brain fields. Recent investigations have shown its adaptability in data compression, generative models, signal manipulation, and basic signal representation.
Each time coordinate is represented by a video frame created by a stack of MLP and convolutional layers. Compared to the basic neural field design, our method considerably cut the encoding time and outperformed common video compression techniques. This paradigm is followed by the recently suggested E-NeRV while also boosting video quality. As shown in Figure 1, they offer flow-guided frame-wise neural representations for movies (FFNeRV). They embed optical flows into the frame-wise representation to use temporal redundancy, drawing inspiration from common video codecs. By combining nearby frames led by flows, FFNeRV creates a video frame that enforces the reuse of pixels from previous frames. Encouraging the network to avoid remembering the same pixel values again across frames dramatically improves parameter efficiency.
FFNeRV beats alternative frame-wise algorithms in video compression and frame interpolation, according to experimental results on the UVG dataset. They suggest using multi-resolution temporal grids with a fixed spatial resolution in place of MLP to map continuous temporal coordinates to corresponding latent features to improve the compression performance further. This is motivated by the grid-based neural representations. Additionally, they suggest utilizing a more condensed convolutional architecture. They use group and pointwise convolutions in the recommended frame-wise flow representations, driven by generative models that produce high-quality pictures and lightweight neural networks. FFNeRV beats popular video codecs (H.264 and HEVC) and performs on par with cutting-edge video compression algorithms using quantization-aware training and entropy coding. Code implementation is based on NeRV and is available on GitHub.
Check out the Paper, Github, and Project. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.