This Artificial Intelligence (AI) Research Demonstrates How Large Language Models (LLMs) are Capable of Self-Improving
Large Language Models (LLMs) may now perform at the cutting edge on various Natural Language Processing (NLP) tasks because of scaling. More significantly, as LLMs are grown to hundreds of billions of parameters, additional features have been revealed: Chain-of-Thought (CoT) prompting shows the strong reasoning ability of LLMs across diverse tasks with or without few-shot examples, and self-consistency further improves the performance by self-evaluating multiple reasoning paths. In-context few-shot learning enables an LLM to perform well on a task it never trained on with only a few examples.
Despite the amazing skills of models trained on enormous text corpora, substantially enhancing the model performances above few-shot baselines still necessitates finetuning on a sizable amount of high-quality supervised datasets. InstructGPT crowdsourced many human responses for various text instructions to better align their model with human instructions. Meanwhile, FLAN and T0 curated tens of benchmark NLP datasets to improve zero-shot task results on unknown tasks. The human brain, on the other hand, is capable of the metacognition process, where human reasoning capacity can be honed without external inputs, despite substantial efforts being made to acquire high-quality supervised datasets.
Researchers at Google and the University of Illinois investigate how an LLM might develop its capacity for reasoning without access to supervised data. Their paper demonstrates that a pre-trained LLM can improve performances for in- and out-of-domain tasks, utilizing only input sequences (without ground truth output sequences) from numerous NLP task datasets.
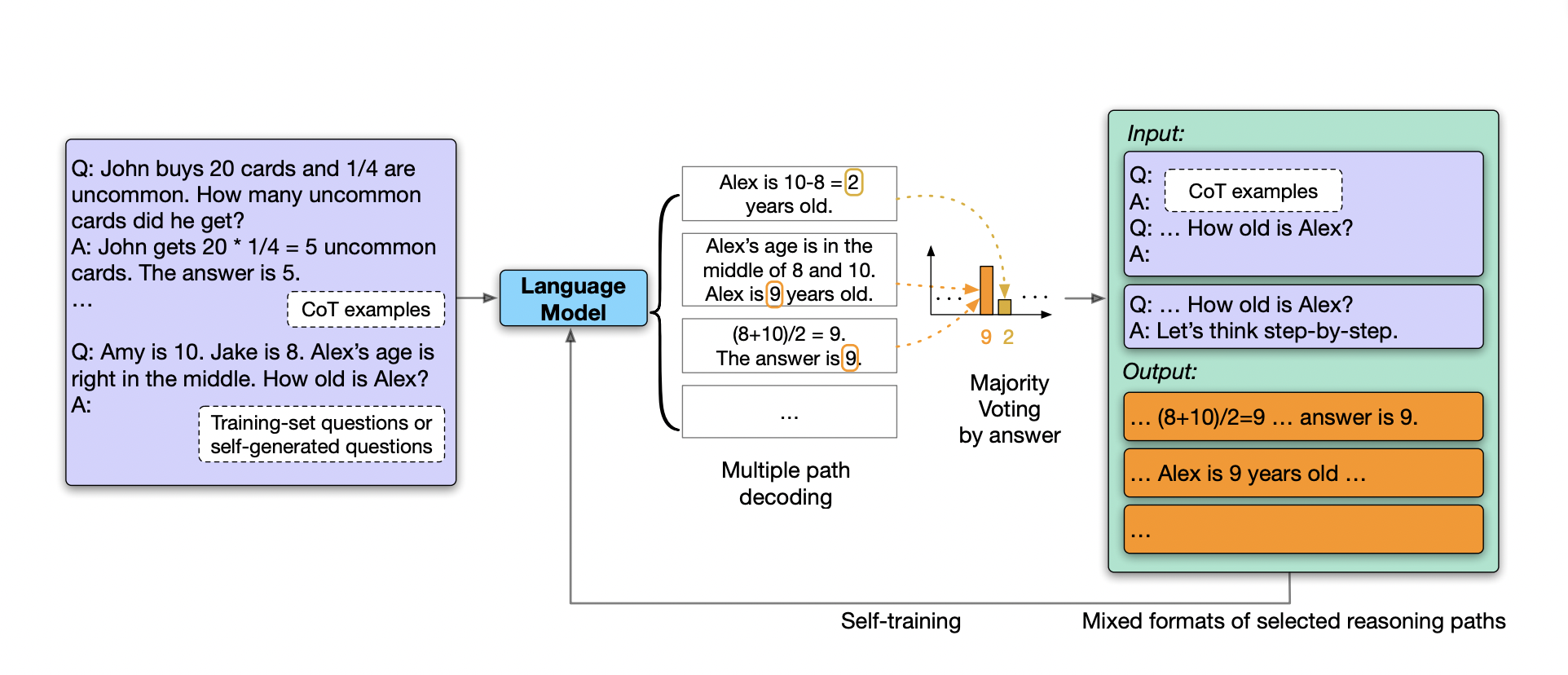
Their approach samples a large number of predictions using few-shot Chain-of-Thought (CoT) prompts, filters out “high confidence” predictions using majority voting, and finetunes the LLM on these high-confidence predictions. In both greedy and multipath evaluations, the final model demonstrates improved reasoning. This model is referred to as the Language Model Self-Improved (LMSI). This is comparable to how a human brain can learn: given a question, it will consider many solutions, conclude on how the question should be answered, and then either learn from or memorize its own answer.
They tested their method using a PaLM-540B LLM that has already been trained. The proposed method not only enhances performance on training tasks (GSM8K, DROP, OpenBookQA, and ANLI-A3) but also on out-of-domain (OOD) test tasks (AQUA, StrategyQA, and MNLI), achieving state-of-the-art results in a variety of tasks without relying on supervised ground truth answers.
Then, to further reduce the amount of human effort needed for model self-improvement, they perform preliminary experiments on self-generating extra input questions, few-shot CoT prompts, and ablation studies on critical hyperparameters of their methodology. The team believes their methodology and compelling empirical findings will spur additional community research on the best ways to use pretrained LLMs without extra human supervision in the future.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.