This Artificial Intelligence (AI) Research From Norway Introduces Tsetlin Machine-Based Autoencoder For Representing Words Using Logical Expressions
Developing word, phrase, and document representation are essential to natural language processing (NLP) success. Such representations improve the efficiency of subsequent tasks like clustering, topic modeling, searching, and text mining by capturing word semantics and similarities.
However simple, the conventional bag-of-words encoding does not consider the words’ placement, semantics, or context within a document. Distributed word representation fills this gap by encoding words as embeddings and low-dimensional vectors.
There are numerous word embedding learning algorithms. The objective is to co-locate comparable or pertinent words to the context in vector space. Word2Vec, FastText, and GloVe, three modern self-supervised approaches, have shown how to construct embeddings from word co-occurrence using a large training set. The more complex language models BERT and ELMO now perform very well in downstream tasks because of the addition of context-dependent embeddings. However, they demand a lot of processing power.
The methods represent words as dense floating point vectors. These vectors are expensive to compute and challenging to interpret because of their size and density. Researchers suggest directly generating embeddings from words as opposed to random floating-point values. Such interpretable embeddings would make computation and interpretation easier by capturing the various meanings of a word with just a few defining words.
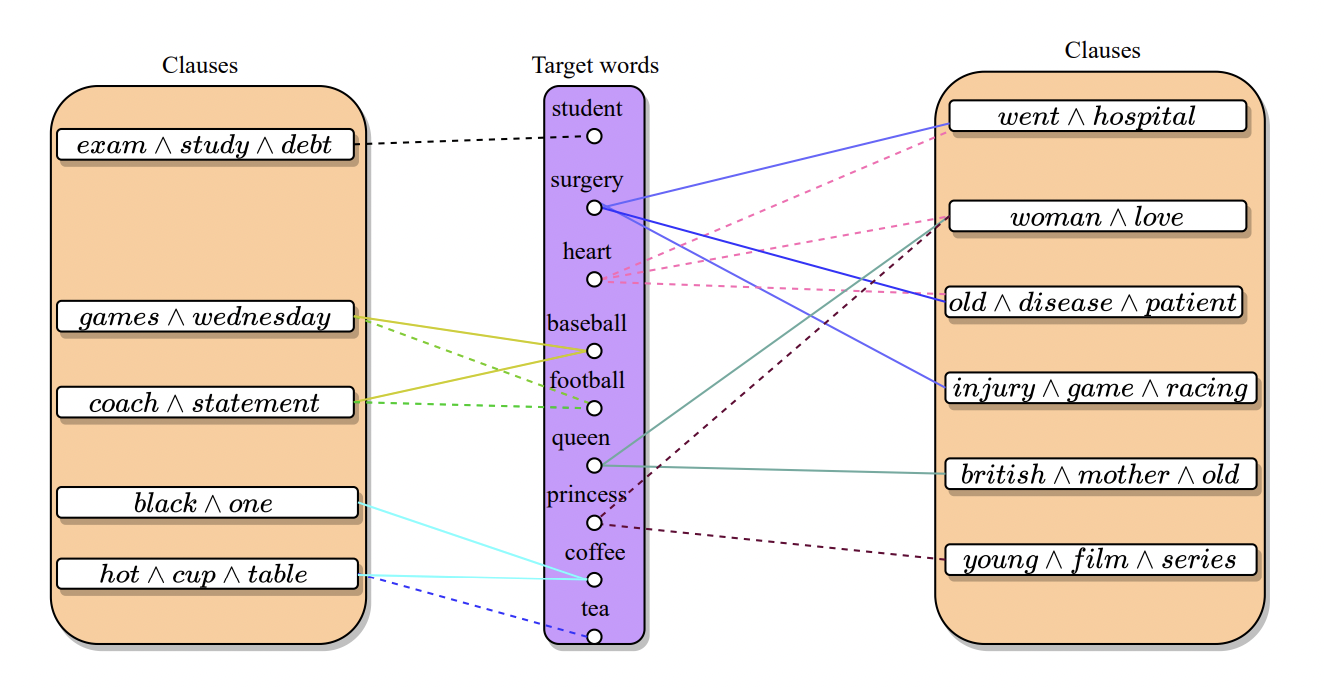
A new study by the Centre for AI Research (CAIR), University of Agder, introduces an autoencoder for constructing interpretable embeddings based on the Tsetlin Machine (TM). By drawing on a sizable text corpus, the TM constructs contextual representations that model the semantics of each word. The context words that identify each target word are used by the autoencoder to construct propositional logic expressions. For instance, the words “one,” “hot,” “cup,” “table,” and “black” can all be used to denote the word “coffee.”
The logical TM embedding is sparser than neural network-based embedding. A logical expression over words makes up each of the 500 truth values that make up the embedding space, for instance. Each target word ties to less than 10% of these phrases for contextual representation. This representation is competitive with neural network-based embedding despite its sparsity and sharpness.
The team tested their embedding on various intrinsic and extrinsic benchmarks with cutting-edge methods. Their method exceeds GloVe on six downstream classification tasks. The study’s findings show that logical embedding can represent words using logical expressions. Because of this structure, each word may be easily broken down into groups of semantic notions, making the representation minimalist.
The team plans to expand their implementation’s use of GPUs to facilitate the creation of expansive vocabularies from larger datasets. They also want to look into how clauses can be used to build embedding at the document and sentence levels, which is useful for tasks like downstream sentence similarity.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.