This Artificial Intelligence (AI) Research Improves both the Lip-Sync and Rendering Quality of Talking Face Generation by Alleviating the one-to-many Mapping Challenge with Memories
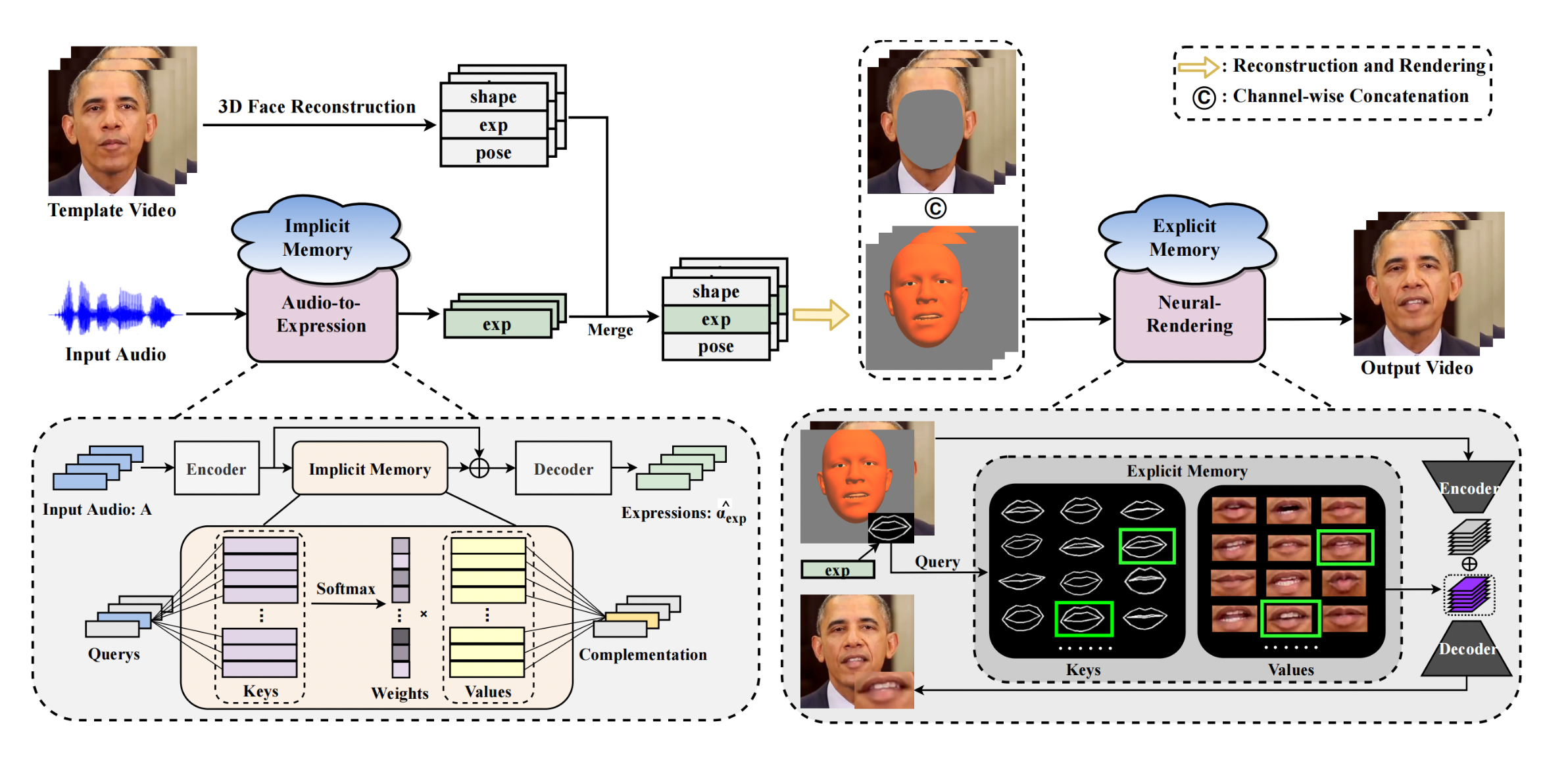
Using talking face creation, it is possible to create lifelike video portraits of a target individual that correspond to the speech content. Given that it provides the interested person’s visual material in addition to the voice, it has a lot of promise in applications like virtual avatars, online conferences, and animated movies. The most widely used techniques for dealing with audio-driven talking face generation use a two-stage framework. First, an intermediate representation is predicted from the input audio; then, a renderer is used to synthesize the video portraits by the expected representation (e.g., 2D landmarks, blendshape coefficients of 3D face models, etc.).By obtaining natural head motions, increasing lip-sync quality, creating an emotional expression, etc. along this road, great progress has been achieved toward improving the overall realism of the video portraiture.
However, it should be noted that talking face creation is intrinsically a one-to-many mapping problem. In contrast, the algorithms mentioned above are skewed towards learning a deterministic mapping from the provided audio to a video. This indicates that there are several possible visual representations of the target individual given an input audio clip due to the variety of phoneme contexts, moods, and lighting conditions, among other factors. This makes it more difficult to provide realistic visual results when learning deterministic mapping since ambiguity is introduced during training. The two-stage framework, which divides the one-to-many mapping challenge into two sub-problems, might help to ease this one-to-many mapping (i.e., an audio-to-expression problem and a neural-rendering problem). Although efficient, each of these two phases is still designed to forecast the data that the input missed, making prediction difficult. As an illustration, the audio-to-expression model learns to create an expression that semantically corresponds to the input audio. Still, it ignores high-level semantics such as habits, attitudes, etc. Compared to this, the neural rendering model loses pixel-level information like wrinkles and shadows since it creates visual appearances based on emotion prediction. This study suggests MemFace, which makes an implicit memory and an explicit memory that follow the sense of the two phases differently, to supplement the missing information with memories to ease the one-to-many mapping problem further.
More precisely, the explicit memory is built non-parametric and customized for each target individual to complement visual features. In contrast, the implicit memory is jointly optimized with the audio-to-expression model to complete the semantically aligned information. Therefore, their audio-to-expression model uses the extracted audio feature as the query to attend to the implicit memory rather than directly using the input audio to predict the expression. The auditory characteristic is combined with the attention result, which previously functioned as semantically aligned data, to provide expression output. The semantic gap between the input audio and the output expression is reduced by permitting end-to-end training, which encourages the implicit memory to associate high-level semantics in the common space between audio and expression.
The neural-rendering model synthesizes the visual appearances based on the mouth shapes determined from expression estimations after the expression has been obtained. They first build the explicit memory for each individual by using the vertices of 3D face models and their accompanying picture patches as keys and values, respectively, to supplement pixel-level information between them. The accompanying picture patch is then returned as the pixel-level information to the neural rendering model for each input phrase. Its corresponding vertices are utilized as the query to obtain similar keys in the explicit memory.
Intuitively, explicit memory facilitates the generation process by enabling the model to selectively correlate expression-required information without generating it. Extensive tests on several commonly used datasets (such as Obama and HDTF) show that the proposed MemFace provides cutting-edge lip-sync and rendering quality, consistently and considerably outperforming all baseline approaches in various contexts. For instance, their MemFace improves the Obama dataset’s subjective score by 37.52% vs to the baseline. Working samples of this can be found on their website.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.