This Artificial Intelligence Research Leverages State-of-the-Art Machine Learning Models, Enabling AI Systems to do Mathematics in English as well as in Logic

")
Can we solve mathematical and logical problems using machine learning? What if we could prove complex mathematical theorems using machine learning? What if there was an automated system to derive and establish new results in basic and advanced mathematics?
This paper takes a significant step in this direction. Most math today is represented in natural language instead of formal language. Formal language means a language understandable by machines. So on, a major step in achieving this goal of automating proofs and derivations of theorems and results depends on Autoformalization. Autoformalization is the process of automatically translating natural language mathematics to formal language. The applications of successful autoformalization tools are huge in theory as well as in practice.
The researchers claimed that the recent advance large language models could understand formal languages, like the recently released ChatGPT, can write somewhat correct code for a given problem statement. However, there is a catch: these models’ success is limited to formal languages with a large corpus of data on the web ( like python, C, etc.). Formal mathematics data is very rare; even the largest formal mathematics library is only 180 MB, which is less than 0.2% of the data on which the large language model Codex is trained. In addition, there is no aligned data between natural language and formal mathematics.

Despite all these issues, the researchers found that the LLMs already have the capability to formalize natural language mathematics (see Figure 1). In addition to translating into syntactically correct Isabelle ( The Isabelle is an automated higher-order logic (HOL) theorem prover, written in Standard ML and Scala ) code, it also grasps the non-trivial reasoning.

This work uses PaLM and Codex as large language models for autoformalization.
How do they assess the ability of LLMs to do autoformalization?
Two interesting natural language mathematical statements from the miniF2F dataset are chosen and prompted to be translated into formal statements in Isabelle using different scales of the PaLM and Codex models. Apart from that, they have used two datasets, MATH (which contains middle and high school mathematical competition problems) and MiniF2F, a benchmark containing 488 mathematical statements with manual formalization by humans. It is unlikely that this data was involved in the pretraining corpus of used LLMs, as the dataset was committed to the repository in March 2022.
The researchers performed three case studies:
- (See Figure 1) They asked LLMs to autoformalize an International Mathematical Olympiad problem in natural language. Codex successfully translated it to Isabelle theorem perfectly. It is a surprising observation as Isabelle code is scarce on the internet, and there is almost no aligned data from natural language to Isabelle on the web. Lastly, the codex can understand non-trivial reasoning. However, PaLM gave a syntactically incorrect output.
- (See Figure 3) When asked, Codex and PaLM were to formalize a grade school problem, and both gave a perfect formalization. Even though formalizations of grade school math problems are rare in interactive theorem provers, the model is able to extrapolate to this type of statement.
- (See Figure 3) Codex gives an incorrect formalization as it assumes the “linear function” as an already known concept in Isabelle, but if we provide a related problem that explains the idea of a line. Then the model can correct itself, demonstrating the few-shot learning capabilities of these models.

But then one question arises, what if the models have memorized it all?
The researchers verified this by searching for Isabelle codes of the problems on the internet with different modifications, but they couldn’t find any related statements. Hence, they are confident that the model had not been memorized it.
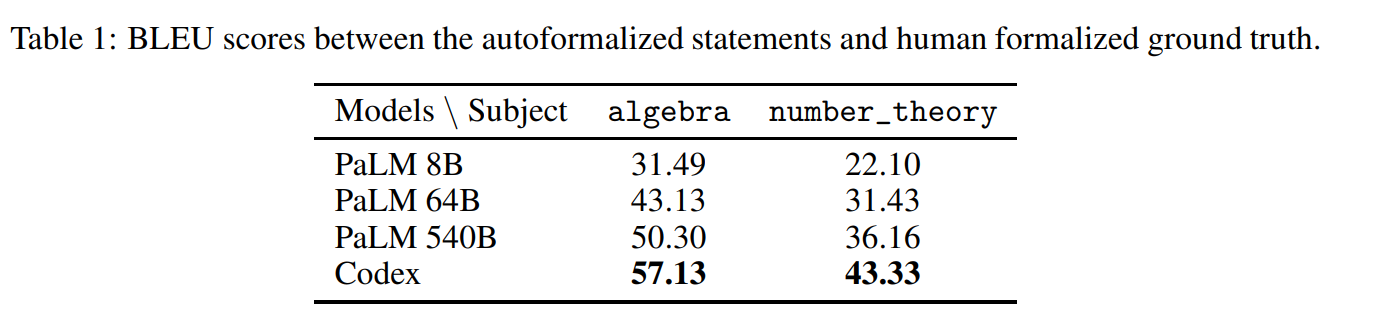
Apart from the above testing, performance with the model size is also observed, showing an increasing trend which means larger LLM means better translation(see Table 1). Human evaluation of failure cases is also done on 150 random problems from the MATH dataset. Results are presented in Table 2.

Now coming to the application of autoformalization, the researchers demonstrated its usefulness by exploring whether neural theorem provers can be improved by training the neural models on proofs of automatically translated theorems.
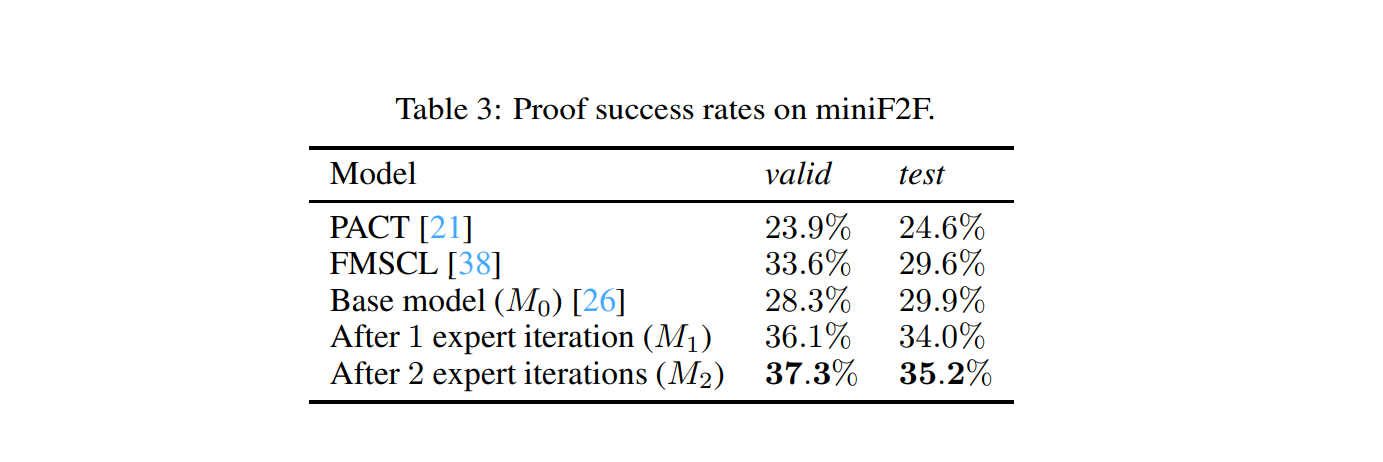
With two rounds of expert iteration with auto-formalization on the MiniF2F dataset, the neural prover achieves a success rate of 37.3% on validation and 35.2% on the test dataset beating the previous state-of-the-art with a margin of 5.6% (see Table 3).
Despite these improvements, there is still a long way to go. The LLM models have some limitations. They cannot differentiate between the product between two numbers and the product between two spaces. So these models are still incapable of translating advanced mathematics statements (see Figure 4). However, when we reverse the task, calling it “informalization,” where we translate Isabelle code into natural language, the LLMs give a success rate of nearly 76%. Hence, the reversed task is easier to model.

Finally, in conclusion, LLMs have a promise regarding autoformalization as models not trained specifically for this task perform well on translation. So, sometime in the near future, it may be able to match human performance on these tasks. Improving these models can also enhance neural provers, which will automate the process of proving theorems.
Check out the Paper and Reference Article. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.