This Machine Learning Paper Presents a General Data Generation Process for Non-Stationary Time Series Forecasting
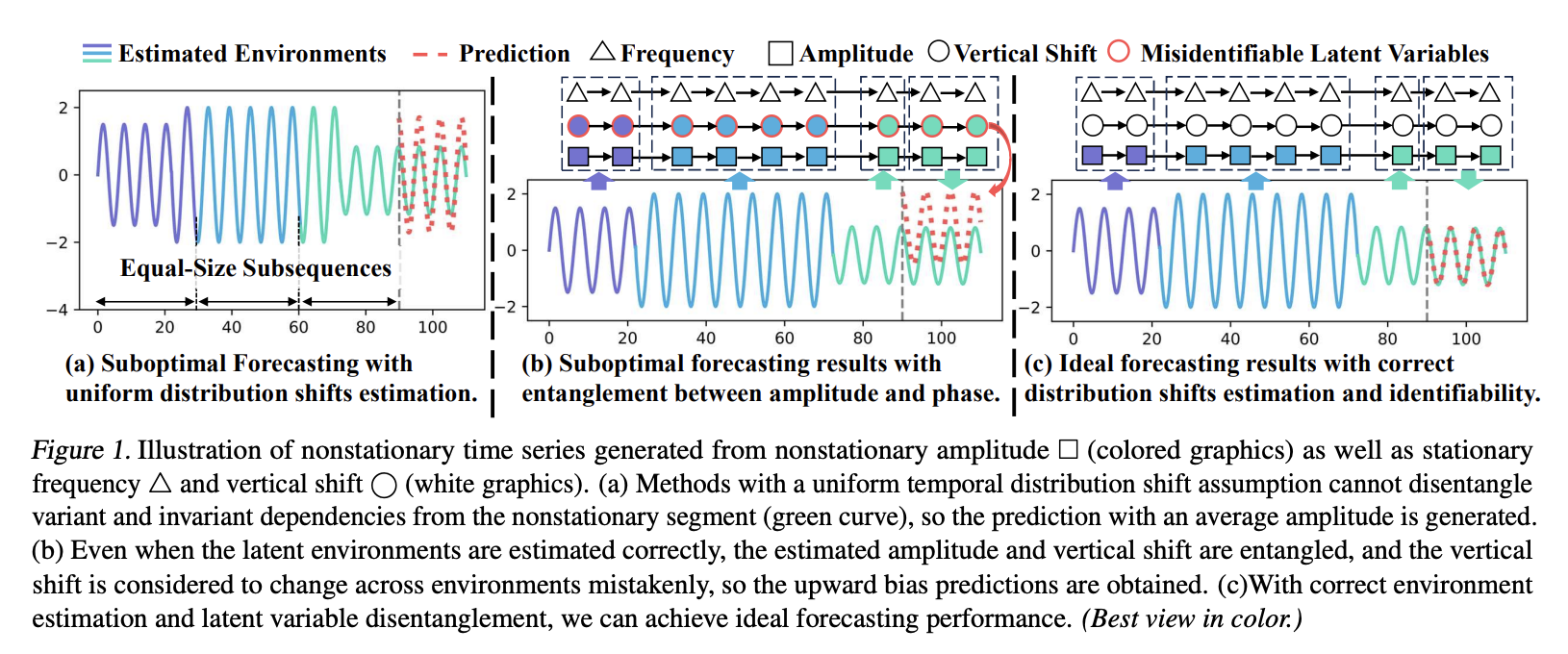
One of the cornerstone challenges in machine learning, time series forecasting has made groundbreaking contributions to several domains. However, forecasting models can’t generalize the distribution shift that changes with time because time series data is inherently non-stationary. Based on the assumptions about the inter-instance and intra-instance temporal distribution shifts, two main types of techniques have been suggested to address this issue. Both stationary and nonstationary dependencies can be separated using these techniques. Existing approaches help reduce the impact of the shift in the temporal distribution. Still, they are overly prescriptive because, without known environmental labels, every sequence instance or segment might not be stable.
Before learning about the changes in the stationary and nonstationary states throughout time, there is a need to identify when the shift in the temporal distribution takes place. By assuming nonstationarity in observations, it is possible to theoretically identify the latent environments and stationary/nonstationary variables according to this understanding.
Researchers from Mohamed bin Zayed University of Artificial Intelligence, Guangdong University, Carnegie Mellon University, and Shantou University sequentially use the assumption of sufficient observations to introduce an identification theory for latent environments. Additionally, they demonstrate that the latent variables, whether stationary or nonstationary, can be distinguished.
Based on the theoretical findings, the researchers developed an IDEA model for nonstationary time series forecasting that can learn discernible latent states. A variational inference framework forms the basis of the proposed IDEA. To estimate latent environments, it employs an autoregressive hidden Markov model. It uses modular prior network designs to identify stationary and nonstationary latent variables. Additionally, they establish evidence of lower bound prior estimation for both stationary and nonstationary latent variables using modular prior networks.
Time-series modeling approaches that rely on causality-based data production processes typically require autoregressive inference and a Gaussian prior. Nevertheless, these prior distributions typically include time-related data and adhere to an amorphous distribution. Disentanglement performance may be inferior if the Gaussian distribution is simply assumed. To address this issue, the team utilizes the modular neural architecture to assess the prior distribution of latent variables, both stationary and nonstationary.
The researchers ran trials on eight real-world benchmark datasets commonly used in nonstationary time series forecasting: ETT, Exchange, ILI(CDC), weather, traffic, and M4. This allowed us to assess how well the IDEA technique performs in real-world circumstances. They start by looking at the long-term forecasting approaches, which include the recently suggested WITRAN, MLP-based methods like DLinear and TimesNet and MICN, and TCN-based methods like MICN. In addition, they consider the approaches predicated on the idea that instances such as RevIN and Nonstationary Transformer change their temporal distribution. They conclude by contrasting the nonstationary forecasting approaches, such as Koopa and SAN, that operate under the premise that the change in the time distribution happens consistently in every case.
The results of the trial show that the IDEA model performs far better than the other baselines on most forecasting tasks. The technique significantly decreases forecasting errors on certain hard benchmarks, such as weather and ILI, and considerably beats the most competitive baselines by a 1.7% to 12% margin. Not only does the IDEA model beat forecasting models like TimesNet and DLinear, which don’t assume nonstationarity, but it also beats RevIN and nonstationary Transformer. These two methods use nonstationary time series data.
The proposed strategy outperforms Koopa and SAN, which imply alterations in the temporal distribution for each time series occurrence, which is quite amazing. The reason is that these techniques have a hard time differentiating between stationary and nonstationary components all at once, and they presuppose that the uniform temporal distribution changes in every time series occurrence, which is rarely the case in reality.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.