This Machine Learning Research Introduces Premier-TACO: A Robust and Highly Generalizable Representation Pretraining Framework for Few-Shot Policy Learning
In our ever-evolving world, the significance of sequential decision-making (SDM) in machine learning cannot be overstated. Unlike static tasks, SDM reflects the fluidity of real-world scenarios, spanning from robotic manipulations to evolving healthcare treatments. Much like how foundation models in language, such as BERT and GPT, have transformed natural language processing by leveraging vast textual data, pretrained foundation models hold similar promise for SDM. These models imbued with a rich understanding of decision sequences, can adapt to specific tasks, akin to how language models tailor themselves to linguistic nuances.
However, SDM poses unique challenges, distinct from existing pretraining paradigms in vision and language:
- There’s the issue of Data Distribution Shift, where training data exhibits varying distributions across different stages, affecting performance.
- Task Heterogeneity complicates the development of universally applicable representations due to diverse task configurations.
- Data Quality and Supervision pose challenges as high-quality data and expert guidance are often scarce in real-world scenarios.
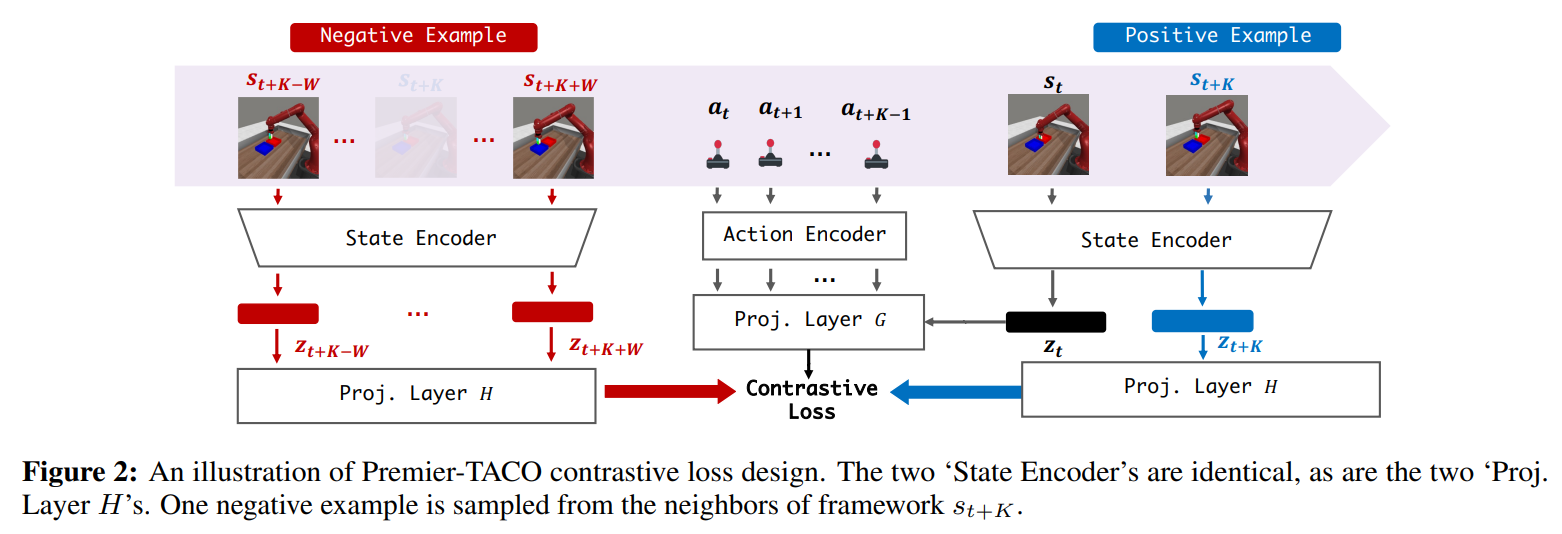
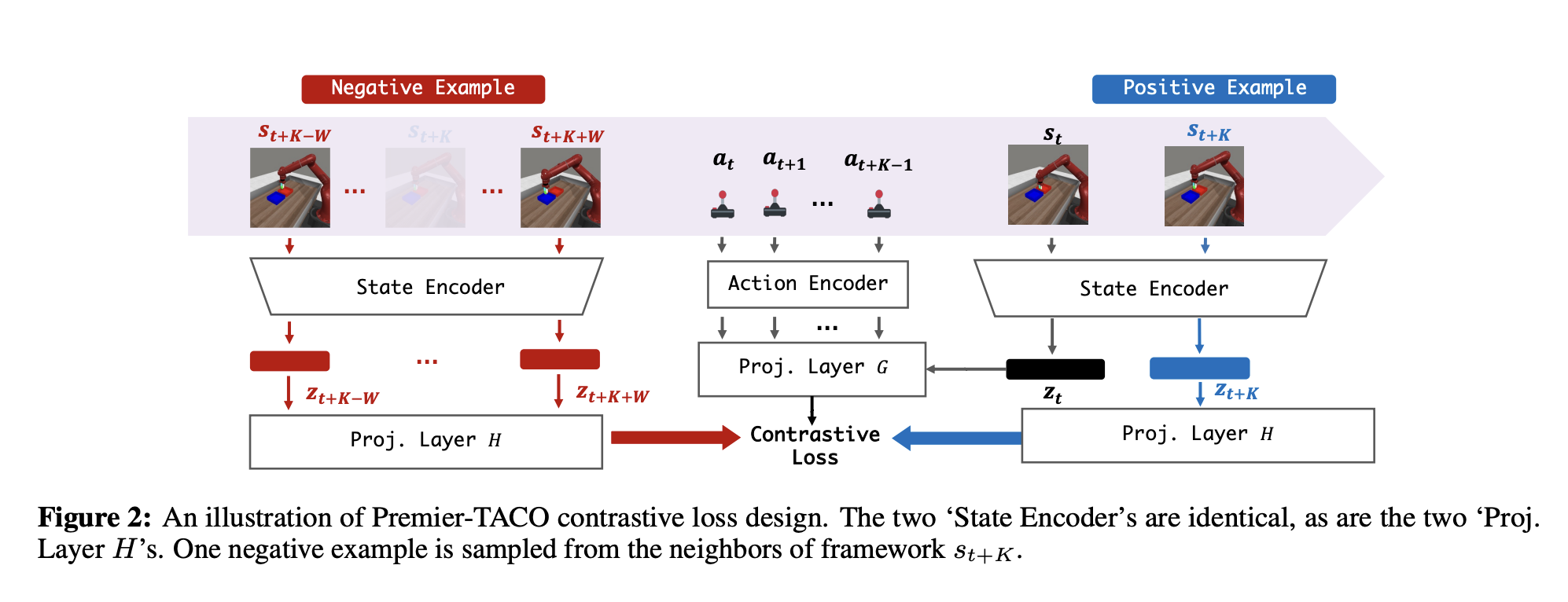
To address these challenges, this paper proposes Premier-TACO, a novel approach focused on creating a universal and transferable encoder using a reward-free, dynamics-based, temporal contrastive pretraining objective (shown in Figure 2). By excluding reward signals during pretraining, the model gains the flexibility to generalize across diverse downstream tasks. Leveraging a world-model approach ensures the encoder learns compact representations adaptable to multiple scenarios.
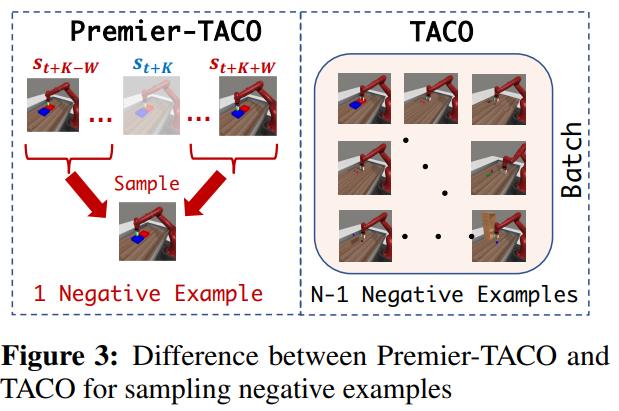
Premier-TACO significantly enhances the temporal action contrastive learning (TACO) objective (difference shown in Figure 3), extending its capabilities to large-scale multitask offline pretraining. Notably, Premier-TACO strategically samples negative examples, ensuring the latent representation captures control-relevant information efficiently.
In empirical evaluations across Deepmind Control Suite, MetaWorld, and LIBERO, Premier-TACO demonstrates substantial performance (shown in Figure 1) improvements in few-shot imitation learning compared to baseline methods. Specifically, on Deepmind Control Suite, Premier-TACO achieves a relative performance improvement of 101%, while on MetaWorld, it achieves a 74% improvement, even showing robustness to low-quality data.
Furthermore, Premier-TACO’s pre-trained representations exhibit remarkable adaptability to unseen tasks and embodiments, as demonstrated across different locomotion and robotic manipulation tasks. Even when faced with novel camera views or low-quality data, Premier-TACO maintains a significant advantage over traditional methods.
Finally, the approach showcases its versatility through fine-tuning experiments, where it enhances the performance of large pretrained models like R3M, bridging domain gaps and demonstrating robust generalization capabilities.
In conclusion, Premier-TACO significantly advances few-shot policy learning, offering a robust and highly generalizable representation pretraining framework. Its adaptability to diverse tasks, embodiments, and data imperfections underlines its potential for a wide range of applications in the field of sequential decision-making.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.